综述
Ray 是一个为了给分布式提供通用的 API 发明出来的分布式计算框架,希望通过简单但通用的抽象编程方式,让系统自动完成所有的工作。Ray 的设计者基于这个理念让 Ray 可以跟 Python 紧密相连,能够通过很少的代码就能处理业务,而其它的并行、分布式内存管理等问题都不用担心,Ray 会根据这些资源的情况自动调度和缩放。
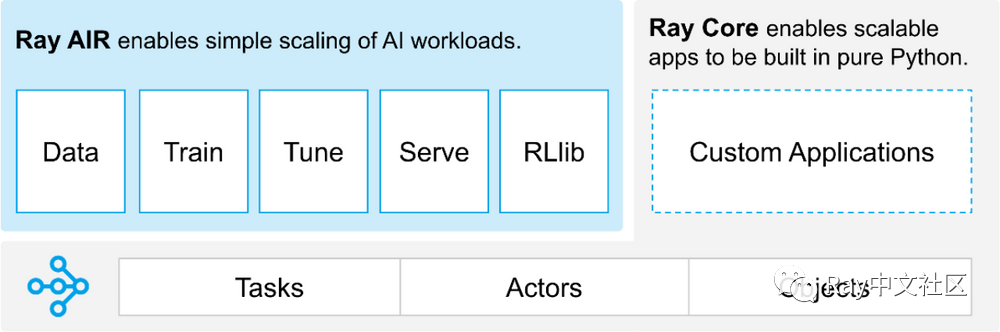
其次 Ray 希望能够对应用程序的一些系统级行为进行控制,如系统的环境变量、参数、故障处理等等。
Ray使 用了包括分布式引用计数和分布式内存等组件,这些组件增加了体系结构的复杂性,但对性能和可靠性来说是必需的。
Ray 构建在 gRPC 的基础上,并且在许多情况下与 gRPC 直接调用的性能一致。与单独使用 gRPC 相比,Ray 使应用程序更容易利用并行和分布式执行、分布式内存共享(通过共享内存对象存储)和动态创建轻量级服务(如通过 gRPC 调用 Actor)。
为了提高可靠性,Ray 的内部协议旨在确保故障期间的正确性只会增加非常低的性能开销。Ray 实现了分布式引用计数协议,以确保内存安全帮助从故障中恢复。
由于 Ray 用户考虑用资源而不是机器来表示他们的计算资源,因此 Ray 应用程序可以简单地从笔记本电脑扩展到集群,而无需任何代码更改。Ray 的分布式调度器和对象管理器旨在实现这种无缝扩展,且开销低。
核心相关系统
Cluster Orchestrators
Ray 提供了更简单运行在 Kubernetes 的方法,可以使用 KubeRay Operator ,它提供了一种在 k8s 中管理 Ray 集群的解决方案,每个 Ray 集群由一个 head 节点和一群 woker 节点组成。你可以通过 KubeRay 来根据所需调整集群大小,同时也支持 GPU 之类的异构计算,也支持有多个版本的 Ray 的集群。
Parallelization Frameworks
与 multiprocessing 或者 Celery 之类的框架相比,Ray 提供了更通用且性能更高的 API。同时支持内存共享。
Data Processing Frameworks
与 Spark、Flink 等框架相比,Ray 提供的 API 更加底层和灵活,更适合作为 “distributed glue” 框架。另一方面 Ray 没有限定一定是数据处理的模式,而是通过功能库的方式提供不同的处理模式。
Actor Frameworks
不像 Erlang 和 Akka 之类的框架,Ray 支持跨语言的操作和使用那个语言原生的库,能够透明地管理无状态的并行计算,显式地支持 Actor 之间共享内存。
HPC Systems
许多 HPC 系统公开了更低级的消息传递接口,虽然很灵活,但开发人员需要付出更多时间和成本。Ray 上的应用程序可以通过初始化 Ray 的 Actor 组之间的通信群来利用这些优化后的 communication primitives。(类似 allreduce)
2.0 带来的新特性
- 原本的 Global Control Store 改名叫 Global Control Service,简称 GCS,有着全新的设计更加简单和可靠。
- 分布式调度器(包括调度策略和置放群组)能让你更方便地扩展功能。
- 在可靠性和容错性方面进行改进,包括从故障节点中恢复 object reconstruction 和 GCS 的容错机制。
- 增加了像 KubeRay 等方便集群管理的一些工具。
架构设计概述
主要概念解释
Task
一个用于远程调用的函数,在不同的调用方的进程上执行,也可以是在不同的机器上执行。Task 可以是无状态的也可以是有状态的(如 Actor)。
Object
应用所需的值,这些是任务返回的或者通过 ray.put创建的值,这些对象是一旦创建就不可以修改的。可以通过 ObjectRef 引用。以下也可能被称为对象。
Actor
有状态的工作进程,Actor 的任务必须使用特定的方式提交给指定的实例,可以在执行过程中修改 Actor 的内部状态。你可以理解为是一个常驻进程,或者是有状态的 Task。
Driver
程序的 root 或者是主程序,一般指放 ray.init 的代码的应用。
Job
来自同个 Driver 的 Task 和 Actor 的集合,Driver 和 Job 是 1:1 映射关系。是一个逻辑上的概念,其含义为运行一次用户侧代码所所涉及到的所有生成的 Task 以及产生的状态的集合。
设计
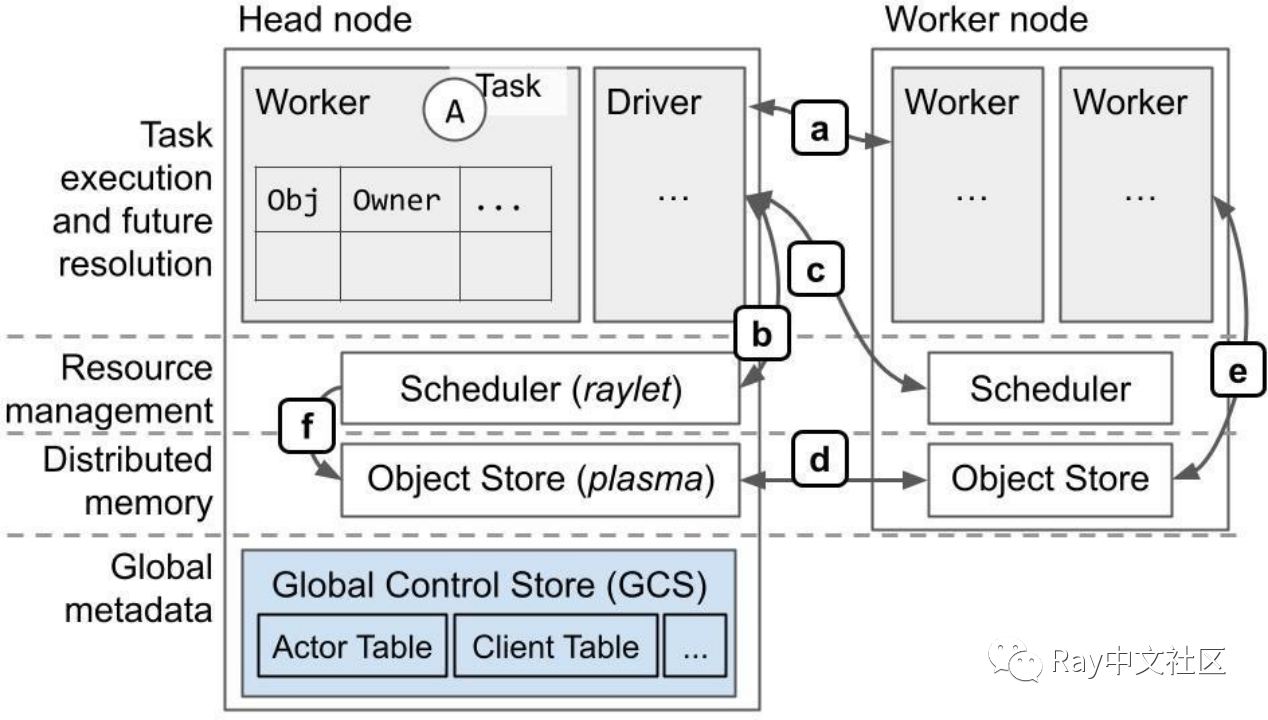
协议概览(大部分通过 gRPC):
a. 任务执行,对象引用计数。
b. 本地资源管理。
c. 远程/分布式资源管理。
d. 分布式对象传输。
e. 大型对象的存储和检索。检索是通过 ray.get 或在任务执行过程中进行。或者用对象的值替换一个任务的ObjectID参数时。
f. 调度器从远程节点获取对象,以满足本地排队任务的依赖满足。
组件
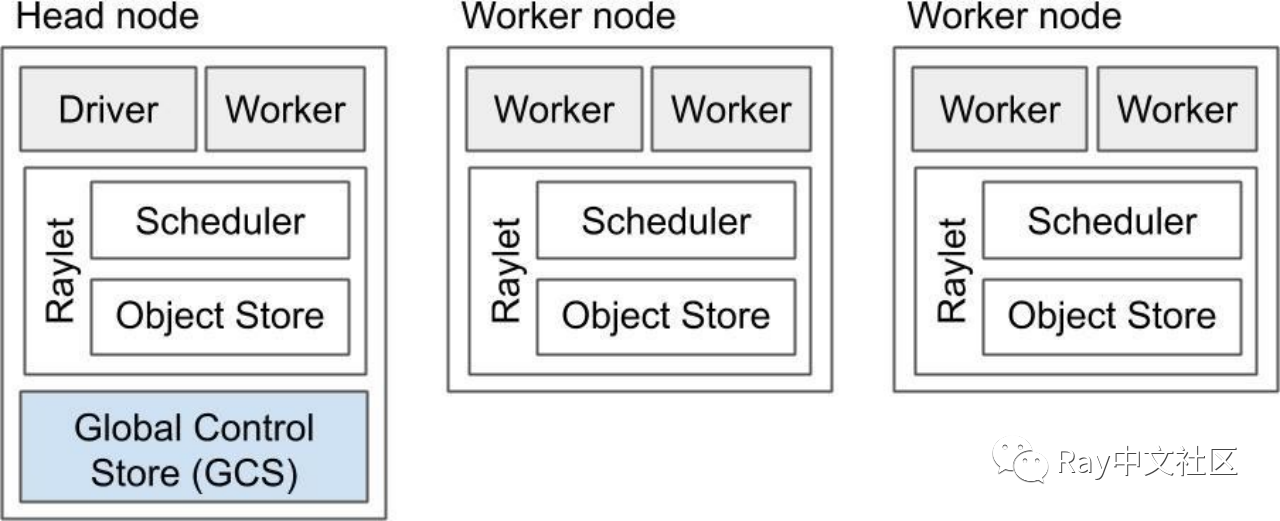
Ray 集群是由一个或者多个 worker 节点组成,每个 worker 节点由以下物理进程组成:
- 一个或多个的 worker 进程,负责任务的提交和执行,worker 进程要么是无状态的,要么是一个 actor。初始工作线程由机器的 CPU 数量决定。每个工作节点会存储:
- 一个 ownership 表,worker 引用的对象的系统元数据,例如引用技术和对象位置。
- 进程内存储,存放一些小对象。
- raylet,用于管理每个节点上的共享资源,与工作进程不同的是,raylet 是在所有 worker 中共享的:
- Scheduler,负责资源管理、任务放置和完成将 Task 的参数存储在分布式的 Object Store 中。
- Object Store,一个共享内存存储,也被称为 Plasma Object Store。负责存储、转移和溢出(spilling,如果 Object Store 满了会移动到外部存储)大型对象。集群中各个 Object Store 共同构建了 Ray 的分布式对象存储。
每一个工作进程和 raylet 都被分配了一个唯一的 28-byte 的标识符和一个 ip 地址、端口。
同样的地址和端口在工作进程死亡后重新恢复时可以重复使用,但是唯一 ID 不会。工作进程和 raylet 是 fate-share 的,一个出故障另外一个就无法使用了。
其中有个节点会被指定为 Head 节点,除了有上述进程外还会托管 GCS 和 Driver。在新版本的 GCS 是一个管理集群的元数据的服务器,比如 actor 的位置、worker 存储的 key-value 对等。GCS 还管理少量的集群几笔的操作包括调度预占用组和 actor 以及确定集群中哪些是成员。一般来说 GCS 中保存的数据很少被调用,但是可以被集群中几乎所有的 worker 节点使用。GCS 容错机制是在 v2 版本中加入的,它可以运行在任何节点或者多个节点,之前只能在指定的节点。
Dirver 是一个用于指定的用于运行最上级的代码的应用的节点,它能提交任务但是并不能在自己上面执行。虽然 Driver 可以在任何节点上运行,但默认情况下只在 Head 节点运行。
Head 节点还包含了其它类似集群级别服务的自动缩放、任务提交等等。
Ownership
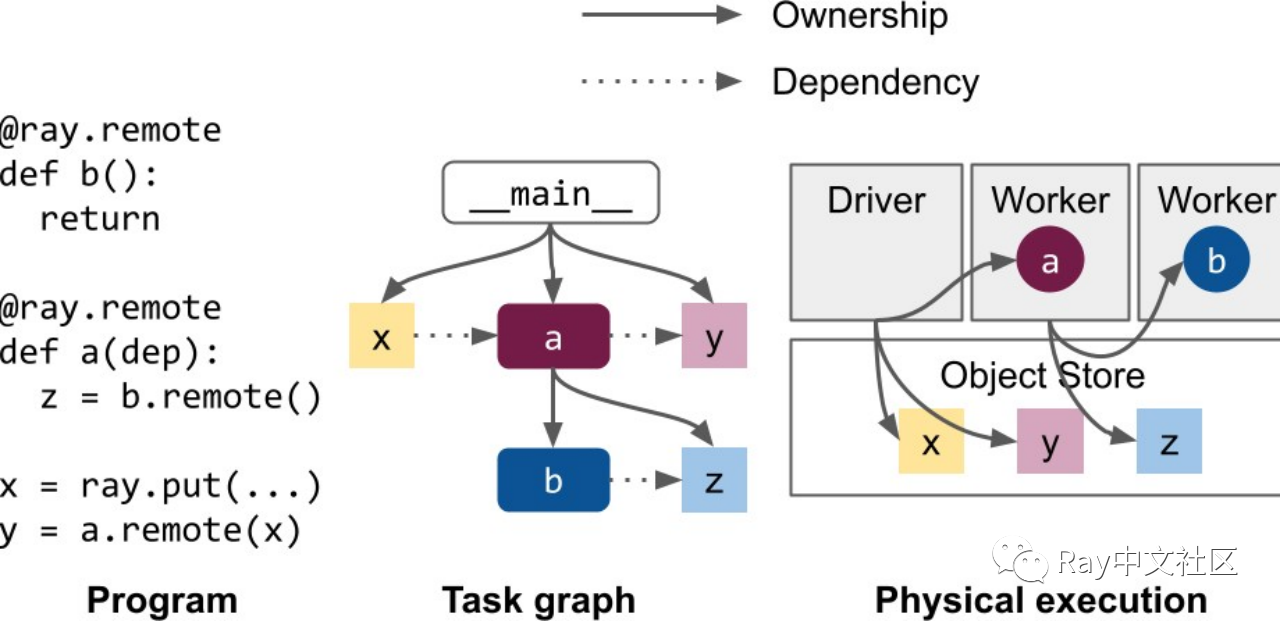
大多数的系统是通过一种叫做 Ownership 的分散控制的方式管理的,这个方式是指每一个 ObjectRef 都是由所在的 worker 进程管理的,该 worker 或者也被叫做 owner 需要确保 Task 的执行、创建 value。
一般有两种方式去创建 ObjectRef,在下面两个例子中,owner 都是实际运行的 worker 的进程。
- x_ref = f.remote()
- x_ref = ray.put()
换句话来说 owner 是生成和初始化 ObjectRef 的 worker,如果 ObjectRef 由 Task 返回,那么这个值是由远程 worker 创建的而不是拿到返回值的 worker。
在 2.0 版本中,这个方式带来了更好的性能和更简单的结构、提升了可靠性,每个 application 是相对独立的,一个远程调用故障了并不会影响另一个。
但 ownership 还是存在一些问题,像如果要解析 ObjectRef ,就必须能够访问对象的 owner,这意味着 object 和 owner 是 fate-share(一个挂掉,另一个一起挂掉)。其次是目前无法转移所有权。
内存模型
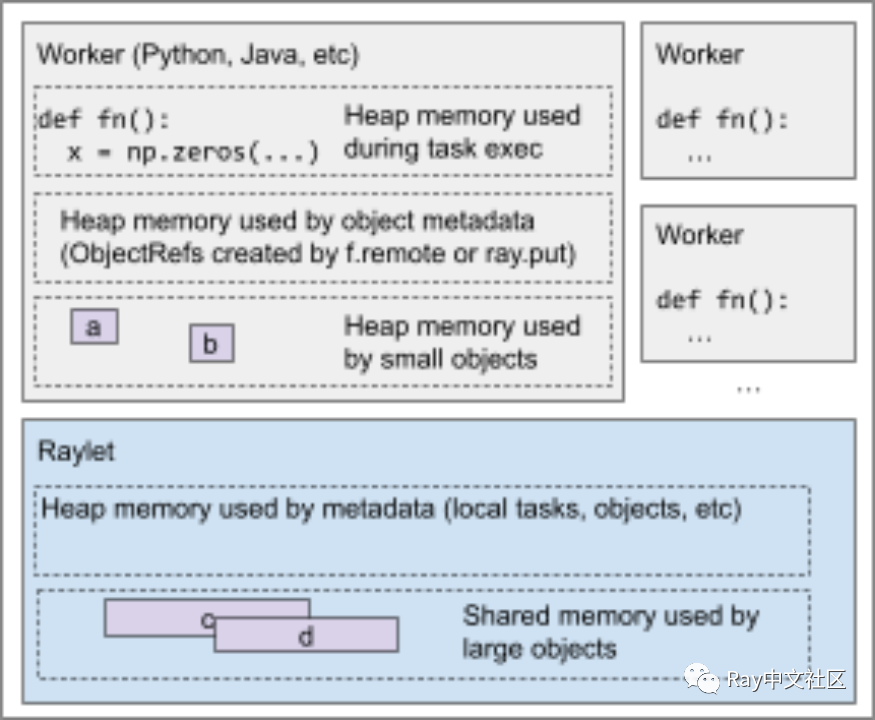
Ray 通过以下方式使用内存:
- Ray 的 worker 在执行任务或者运行 Actor 时会使用堆内存,由于 Ray 的 Task 和 Actor 一般是并行运行,开发人员应该关注每个 Task 的堆内存的情况。如果内存压力过大,Ray 会自动释放掉消耗内存大的进程。
- 当一个 worker 调用 ray.put() 或者从一个 Task 返回时,它会将提供的值复制到 Ray 的共享内存对象存储中。然后 Ray 会让这些对象在整个集群中可访问,在发生故障时尝试恢复它们,如果对象存储超过其配置的容量,则将它们转移其它存储设备,并在所有 ObjectRef超出范围时将它们垃圾回收。对于可以被 zero-copy 的反序列化的值,会在取出时将指向共享缓冲区的指针给 worker,其它则是被反序列化到接收的 worker 的堆内存中。
- 如果 Object 足够小(默认 100 kb),Ray 将直接把值存储在 owner 的内存中,而不是在 Raylet 里的共享对象存储。任何其它使用这个对象的 worker 都会把值直接复制到自己的内存里。同样 Ray 也会对他们进行垃圾回收。
- Ray 的元数据也会使用堆内存,大部分元数据都很小,可能就几 kb。例如:
- GCS 的所有 Actor、所有节点、所有的预占用组集群。
- Raylet 的本地排队的 Task、这些任务的对象参数、对象。
- Worker 的提交了等待处理的任务或者可能需要重新通过 lineage reconstruction 执行的。拥有的对象等等。
语言运行时
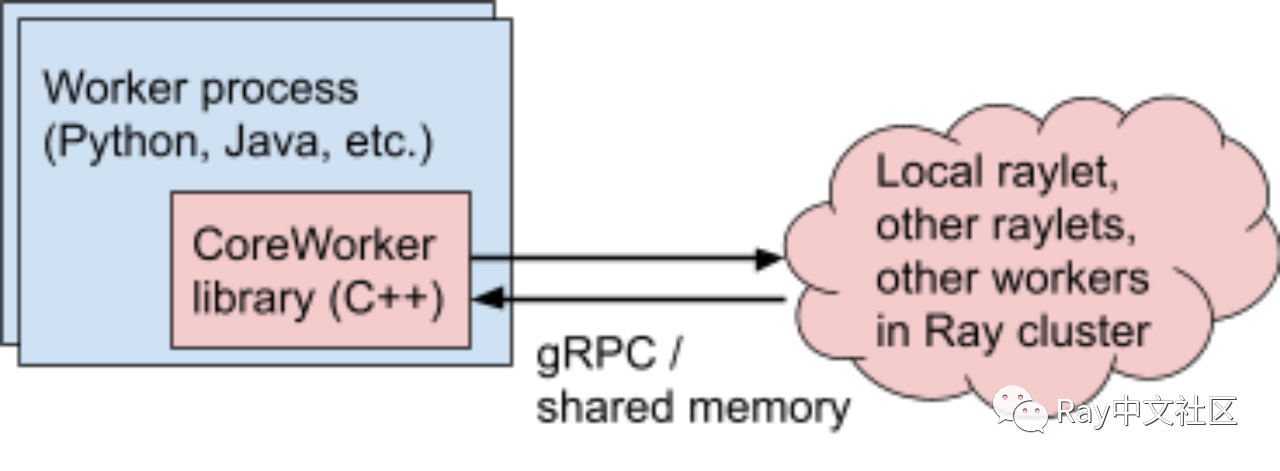
所有 Ray 核心组件都在 C++ 中实现。Ray 通过一个称为“core worker”的 C++ 库支持Python、Java 和 C++ 前端。该库实现了所有权表、进程内存储,并管理与其他工作程序和 raylet 的 gRPC 通信。
Task 的生命周期
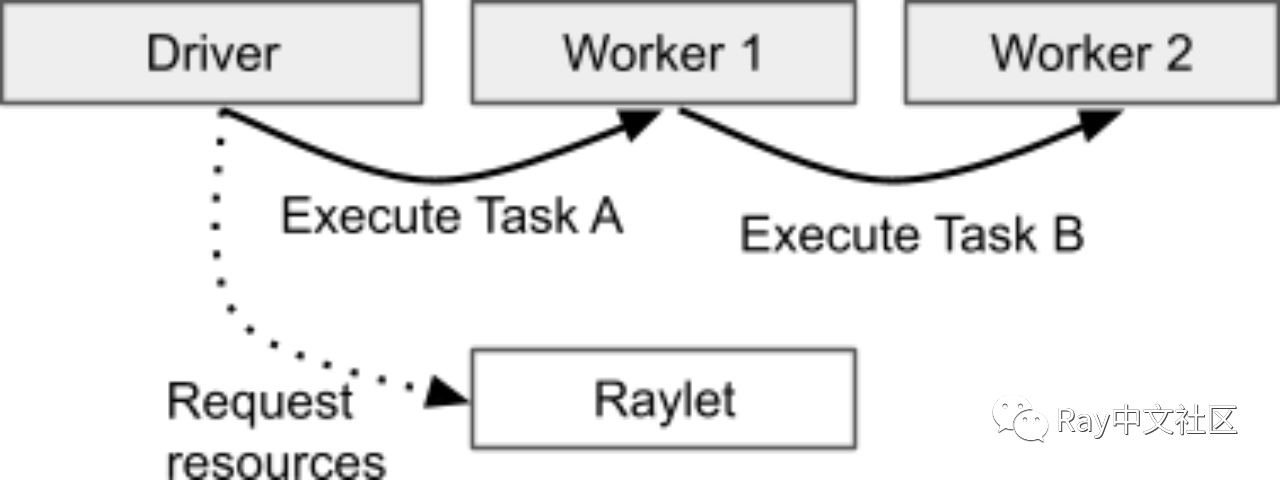
所有者需要能够指定被提交来的任务并且将 ObjectRef 解析成一个普通的值。Driver 去 Raylet 中请求需要的值,将值和 Task A 都交给 Worker 1 运行,Driver 拥有 Task A 结果的所有权,而 Worker 1 有 TaskB 的所有权。
所有者可以将普通的 Python 对象作为任务参数传递,如果参数传递的值很小,会直接将这个值从所有者的内存中复制到 Task 中,让执行者可以直接引用。如果传递的参数很大,所有者会先通过 ray.put 放入共享对象存储,然后将 ObjectRef 作为参数传递。
Ray 会在每一次自动进行上面的流程,如果你喜欢两个 Task 共用一个请显式调用 put。
所有者也可以直接将其它的 ObjectRef 作为任务参数传递,如果 ObjectRef 对应的值很小,会直接放到 Task 的 specification 中,否则传递 ObjectRef 。任务执行时会将 ObjectRef 解析成具体的值。
一旦所有任务依赖项就绪,所有者就从分布式调度器请求资源来执行任务。分布式调度器尝试获取资源,并通过分布式内存将 Task 的 specification 中的任何 ObjectRef 参数获取到本地节点。一旦资源和参数都可用,调度程序就会批准请求。
所有者通过 gRPC 将 Task 的 specification 发送给 worker 来调度。执行 Task 后 worker 必须存储返回的值。如果返回的值很小会直接返回给所有者,如果很大会存到共享内存存储将 ObjectRef 返回,允许所有者引用返回值而不需要先拿到本地节点。
当 Ray 的 Task 第一次被调用时,它会被存储到 GCS 中,稍后会由被租用的 worker 获取出函数的定义进行运行。
Task 可能在运行过程中可能会出现应用级错误(worker 进程仍然是活跃的状态)或者是系统级错误(worker 进程已经死亡或者故障)中断抛出。
默认情况下,由于应用程序级别错误而失败的任务不会自动重试。异常被捕获并存储为任务的返回值。在 2.0 中,用户可以传递应用程序级异常的白名单,Ray 可以自动重试。由于系统级错误而失败的任务会自动重试,你可以指定最多重试次数。
Object 的生命周期
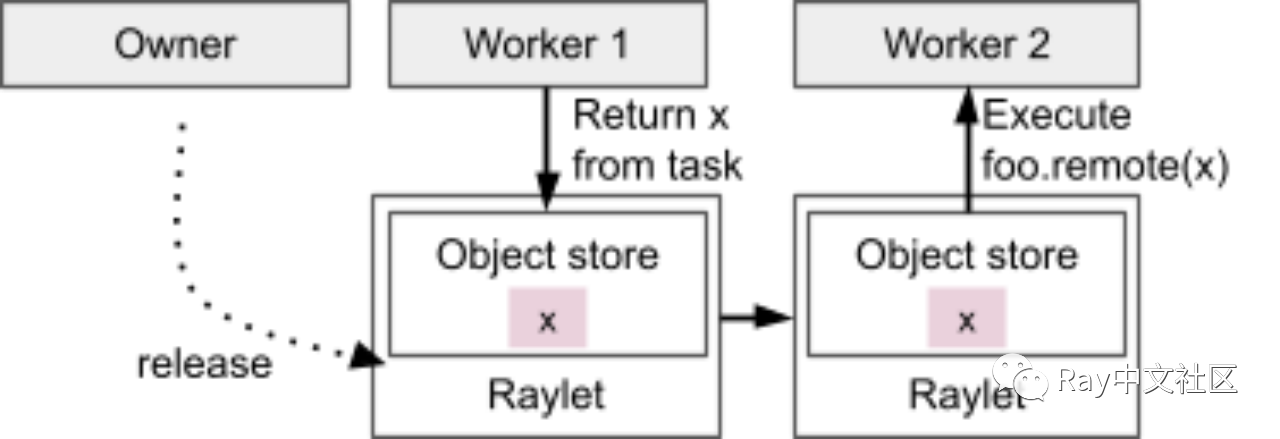
对象是一个不可变的值,可以从 Ray 集群中的任何位置存储和引用。对象的所有者是通过提交创建任务或调用 ray.put 创建初始化 ObjectRef 的 worker。所有者负责管理对象的生存期。Ray 保证如果所有者活着,对象最终可能会被解析为其值(或者在工作程序失败的情况下抛出错误)。如果所有者已死亡,尝试获取对象的值将引发异常,即使仍然存在对象的物理副本。
每个工作程序存储其拥有的对象的引用计数。仅在以下操作期间计算引用:
- 向任务传递 ObjectRef 或包含 ObjectRef 作为参数的对象。
- 从任务中返回 ObjectRef 或包含 ObjectRef 的对象。
对象可以存储在所有者的进程内存存储或分布式对象存储中。进程内内存存储是在所有者的堆上分配的,不强制限制存储量。因为 Ray 只存储很小的对象。过多的小对象存储在内存中可能会引起内存不足的问题而导致进程被结束。存储在分布式对象存储的对象首先会存储在共享内存存储中,共享内存存储默认是机器内存的 30%,在达到上限后转移到本地磁盘上。
你可以通过 ray.get 将 ObjectRef 转为实际的值或者是将 ObjectRef 作为参数传递,具体的执行者会自动解析。
如果出现系统级的故障,对象存储在分布式内存存储中,并且该对象的所有副本都因 raylet 故障而丢失,则该对象就丢失了。Ray 会尝试通过重建的方式去恢复这个对象,如果所有者进程也死亡了,则无法重建。
Actor 的生命周期

当在 Python 中创建 Actor 时,将构建一个特殊任务,称为 Actor 创建任务,该任务运行 Actor 的 Python 构造函数。创建的 worker 等待创建任务的所有依赖项就绪,类似于普通任务。一旦完成, worker 将向 GCS 异步注册参与者。GCS 通过调度 Acotr 创建任务来创建 Actor。这与普通任务的调度类似,只是在 Actor 进程的生命周期内获取其指定的资源。
同时,创建 actor 的 Python 调用立即返回一个 “actor handle” ,即使尚未安排 actor 创建任务,也可以使用该句柄。在参与者创建任务完成之前,不会调度将 actor handle 相关的任务。有关详细信息,请参见 Actor 创作。
Actor 的执行与正常任务执行类似,主要有两个区别:
- 默认情况下 Actor 已经不需要从调度器中获取资源了,当被创建时就已经获取了。
- 对于 Actor 的每个调用方,任务的执行顺序与提交顺序相同。
当 Actor 的创建者退出时且集群中没有其它还没结束的 actor handle 时会自动被清理。当然你也可以显式清理。
在某些情况下,可能不需要顺序执行。为了支持这样的场景,Ray 还提供了一个选项,通过它可以使用事件循环并发运行任务,或者使用线程并行运行多个任务。从调用者的角度来看,向这些参与者提交任务与向常规参与者提交任务相同。唯一的区别是,当任务在参与者上运行时,它被发布到后台线程或线程池,而不是直接在主线程上运行。Ray API(如任务提交和 Ray.get)是线程安全的,但用户需要负责其它部分的线程安全。
故障模型
系统模型
Ray 集群中的任意一个非 Head 的节点的丢失是不影响集群的,Head 节点托管了 GCS,但在 2.0 中,允许 GCS 重启到其它节点来减少对集群的干扰。
所有节点都被分配了一个唯一的标识符,并通过心跳相互通信。GCS 负责决定集群的成员资格,即哪些节点当前处于活动状态。GCS 将删除任何超时的节点 ID,这意味着必须使用不同的节点 ID 在该节点上启动新的 raylet,以便重新使用物理资源。如果一条仍然活跃的的 Ray 收到它已经超时,它就会退出。节点的故障检测当前不处理网络分区问题:如果从 GCS 分区了工作节点,它将超时并标记为不可用。
每个 raylet 向 GCS 报告任何本地的 worker 进程的死亡情况。GCS 会广播这些故障事件,并使用它们让位置在故障节点的已注册的 Actor 死亡。所有 worker 进程的命运都与其节点上的 raylet 共享。
raylets 负责防止 worker 工作进程失败后集群资源和系统状态发生泄漏问题。对于失败的 worker 进程(本地或远程),每个 raylet 负责:
- 通过杀死任何故障的 worker 进程来释放任务执行所需的集群资源,如 CPU。故障的worker 发出的任何未完成的资源请求也将被取消。
- 释放该 worker 持有的在分布式对象内存存储的对象。
应用程序模型
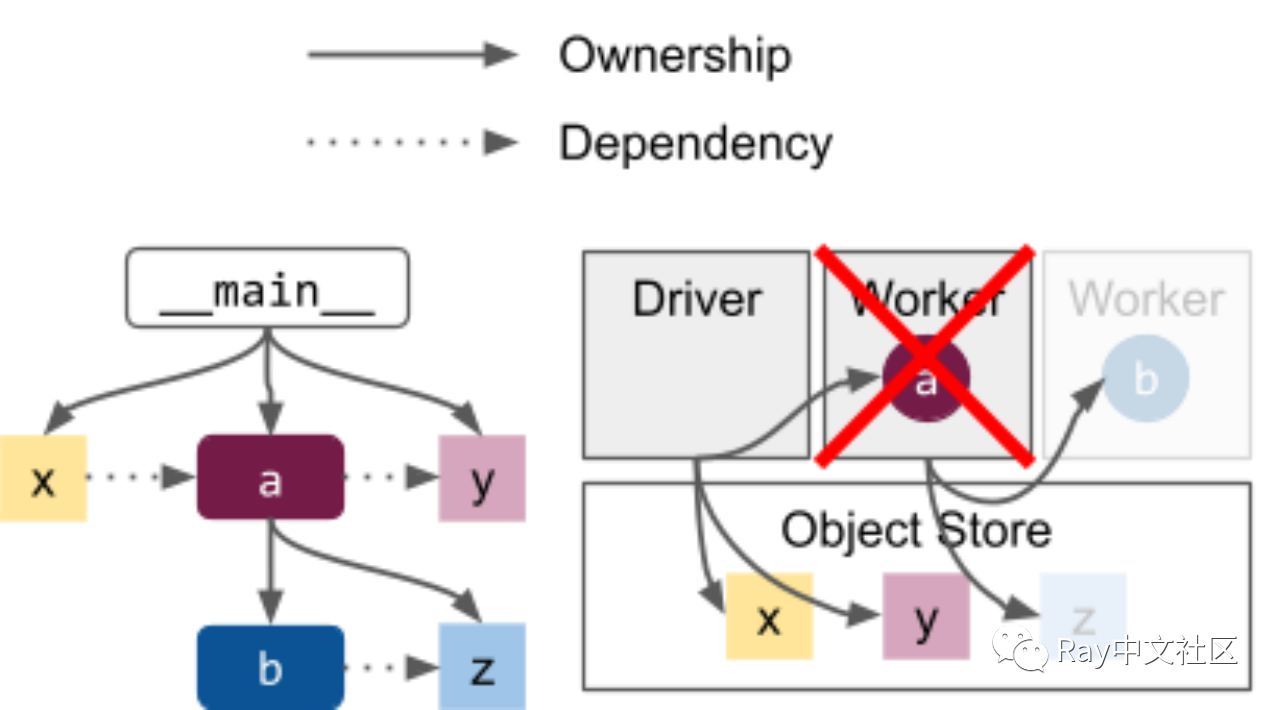
系统故障模型意味着 Ray 里面的任务和对象将与所有者共享命运。例如,如果在这种情况下运行“a”的 worker 失败,那么将收集在其子树(图中灰色的 “b” 和 “z”)中创建的所有对象和任务。如果 “b” 是在 “a” 的子树中创建的 actor(参见 Actor 死亡),则同样适用。
- 如果尝试获取这个发生了错误的对象的值,任何活动进程会收到应用级异常。如上图, Driver 会在 get 结果时收到异常。
- 你可以通过让不同的 Task 放到不同的子树(调用嵌套的函数),故障可以彼此隔离。
- 应用程序与 Driver 是命运共享的,如果 Driver 挂了整个执行过程都会故障。
如果希望避免命运共享(fate-share),可以将它变为独立的 Actor 就不会受到 Driver 证明周期的影响,变为 Actor 后只能通过显式调用方法来销毁它。
1.3 开始 Ray 可以通过将对象放到其它存储空间来实现持久化,2.0 开始 Ray 默认会为普通 Task 启用对象重建。
作者介绍:大家好!我是 Andy.Qin,一个想创造哆啦 A 梦的 Maker,连续创业者。我最熟悉的领域是分布式应用开发、高并发架构设计,其次是机器学习、自然语言处理和理解方向。我对开源社区和开源项目的建设也有极大的热忱,期望能与大家多多交流讨论!
更多深度好文,可以来我我的博客:https://qin.news
目前也在招聘中:【可话】招聘高级后端 | 大数据工程师本次利用业务时间,花了一个月翻译了将近60多页的Ray2.0架构白皮书,期望对大家能够有所帮助!大家有任何问题或者疑问,欢迎留言与我交流!