1请先搜索,在提问哦,搜索的过程也是提炼明确问题的过程,如果没有找到相关的问题和答案,建议按照以下模板清晰的描述问题!
2问题模板
【Ray使用环境】生产
【Ray版本】2.0.0
【使用现场】
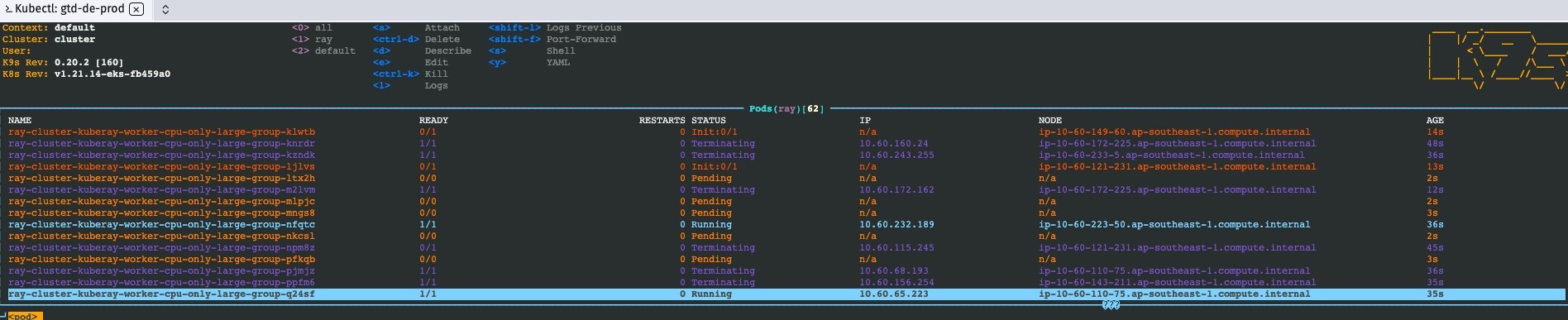
以下是我部署kuberay的yaml文件,当时添加了多个资源组(4核8g,4核16g,6核32g)和自动扩缩容的功能,但是部署上去后发现请求6核32g(cpu-only-large-group)的worker节点后,k8s会不停地创建和销毁pod,直至整个集群的资源被占满
【问题复现】
---
# Source: ray-cluster/templates/raycluster-service.yaml
apiVersion: v1
kind: Service
metadata:
# labels:
# app.kubernetes.io/name: kuberay-metrics
# ray.io/cluster: ray-cluster-kuberay
name: ray-cluster-kuberay-metrics-svc
annotations:
prometheus.io/scrape: "true"
prometheus.io/path: /metrics
prometheus.io/port: "8080"
spec:
ports:
- name: metrics
port: 8080
protocol: TCP
targetPort: 8080
selector:
app.kubernetes.io/name: kuberay
ray.io/cluster: ray-cluster-kuberay
type: ClusterIP
---
# Source: ray-cluster/templates/raycluster-cluster.yaml
apiVersion: ray.io/v1alpha1
kind: RayCluster
metadata:
labels:
app.kubernetes.io/name: kuberay
helm.sh/chart: ray-cluster-0.3.0
app.kubernetes.io/instance: ray-cluster
app.kubernetes.io/version: "1.0"
app.kubernetes.io/managed-by: Helm
name: ray-cluster-kuberay
spec:
enableInTreeAutoscaling: true
autoscalerOptions:
# upscalingMode is "Default" or "Aggressive."
# Conservative: Upscaling is rate-limited; the number of pending worker pods is at most the size of the Ray cluster.
# Default: Upscaling is not rate-limited.
# Aggressive: An alias for Default; upscaling is not rate-limited.
upscalingMode: Default
# idleTimeoutSeconds is the number of seconds to wait before scaling down a worker pod which is not using Ray resources.
idleTimeoutSeconds: 60
# image optionally overrides the autoscaler's container image.
# If instance.spec.rayVersion is at least "2.0.0", the autoscaler will default to the same image as
# the ray container. For older Ray versions, the autoscaler will default to using the Ray 2.0.0 image.
## image: "my-repo/my-custom-autoscaler-image:tag"
# imagePullPolicy optionally overrides the autoscaler container's image pull policy.
imagePullPolicy: Always
# resources specifies optional resource request and limit overrides for the autoscaler container.
# For large Ray clusters, we recommend monitoring container resource usage to determine if overriding the defaults is required.
resources:
limits:
cpu: "500m"
memory: "512Mi"
requests:
cpu: "500m"
memory: "512Mi"
headGroupSpec:
serviceType: ClusterIP
rayStartParams:
block: "true"
dashboard-host: "0.0.0.0"
node-ip-address: "$MY_POD_IP"
num-cpus: "1"
port: "6379"
redis-password: "LetMeInRay"
replicas: 1
template:
spec:
imagePullSecrets:
- name: harbor-bybit
- name: harbor-infra
containers:
- volumeMounts:
- mountPath: /tmp/ray
name: log-volume
name: ray-head
image: ***********/bigdata/ray:prod-2.0.1-py38-ai2.0
imagePullPolicy: Always
resources:
limits:
cpu: 4
memory: 8Gi
requests:
cpu: 2
memory: 2Gi
env:
- name: TYPE
value: head
- name: MY_POD_IP
valueFrom:
fieldRef:
fieldPath: status.podIP
- name: MLFLOW_TRACKING_URI
value: http://*******
- name: PLATFORM_ENV
value: prod
- name: HDFS_CLUSTER_NAME
value: victoria
- name: RAY_OVERRIDE_RESOURCES
value: '{"CPU":0, "GPU":0}'
volumes:
- emptyDir: {}
name: log-volume
affinity:
{}
tolerations:
[]
nodeSelector:
{}
metadata:
annotations:
{}
labels:
groupName: headgroup
rayNodeType: head
rayCluster: ray-cluster-kuberay
app.kubernetes.io/name: kuberay
helm.sh/chart: ray-cluster-0.3.0
app.kubernetes.io/instance: ray-cluster
app.kubernetes.io/version: "1.0"
app.kubernetes.io/managed-by: Helm
workerGroupSpecs:
- rayStartParams:
block: "true"
node-ip-address: "$MY_POD_IP"
redis-password: "LetMeInRay"
replicas: 0
minReplicas: 0
maxReplicas: 4
groupName: cpu-only-large-group
template:
spec:
imagePullSecrets:
- name: harbor-bybit
- name: harbor-infra
initContainers:
- name: init-myservice
image: busybox:1.28
command: ['sh', '-c', "until nslookup $RAY_IP.$(cat /var/run/secrets/kubernetes.io/serviceaccount/namespace).svc.cluster.local; do echo waiting for myservice; sleep 2; done"]
containers:
- volumeMounts:
- mountPath: /tmp/ray
name: log-volume
name: ray-worker
image: ******/bigdata/ray:prod-2.0.1-py38-ai2.0
imagePullPolicy: Always
resources:
limits:
cpu: 6
memory: 32Gi
requests:
cpu: 1
memory: 1Gi
env:
- name: TYPE
value: worker
- name: MY_POD_IP
valueFrom:
fieldRef:
fieldPath: status.podIP
- name: RAY_DISABLE_DOCKER_CPU_WARNING
value: "1"
- name: CPU_REQUEST
valueFrom:
resourceFieldRef:
containerName: ray-worker
resource: requests.cpu
- name: MY_POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: MLFLOW_TRACKING_URI
value: http://****
- name: PLATFORM_ENV
value: test
- name: HDFS_CLUSTER_NAME
value: testcluster
ports:
- containerPort: 80
protocol: TCP
volumes:
- emptyDir: {}
name: log-volume
affinity:
{}
tolerations:
[]
nodeSelector:
{}
metadata:
annotations:
key: value
labels:
rayNodeType: worker
groupName: cpu-only-large-group
rayCluster: ray-cluster-kuberay
app.kubernetes.io/name: kuberay
helm.sh/chart: ray-cluster-0.3.0
app.kubernetes.io/instance: ray-cluster
app.kubernetes.io/version: "1.0"
app.kubernetes.io/managed-by: Helm
- rayStartParams:
block: "true"
node-ip-address: "$MY_POD_IP"
redis-password: "LetMeInRay"
replicas: 0
minReplicas: 0
maxReplicas: 6
groupName: cpu-only-medium-group
template:
spec:
imagePullSecrets:
- name: harbor-bybit
- name: harbor-infra
initContainers:
- name: init-myservice
image: busybox:1.28
command: ['sh', '-c', "until nslookup $RAY_IP.$(cat /var/run/secrets/kubernetes.io/serviceaccount/namespace).svc.cluster.local; do echo waiting for myservice; sleep 2; done"]
containers:
- volumeMounts:
- mountPath: /tmp/ray
name: log-volume
name: ray-worker
image: ******/bigdata/ray:prod-2.0.1-py38-ai2.0
imagePullPolicy: Always
resources:
limits:
cpu: 4
memory: 16Gi
requests:
cpu: 1
memory: 1Gi
env:
- name: TYPE
value: worker
- name: MY_POD_IP
valueFrom:
fieldRef:
fieldPath: status.podIP
- name: RAY_DISABLE_DOCKER_CPU_WARNING
value: "1"
- name: CPU_REQUEST
valueFrom:
resourceFieldRef:
containerName: ray-worker
resource: requests.cpu
- name: MY_POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: MLFLOW_TRACKING_URI
value: http://*****
- name: PLATFORM_ENV
value: test
- name: HDFS_CLUSTER_NAME
value: testcluster
ports:
- containerPort: 80
protocol: TCP
volumes:
- emptyDir: {}
name: log-volume
affinity:
{}
tolerations:
[]
nodeSelector:
{}
metadata:
annotations:
key: value
labels:
rayNodeType: worker
groupName: cpu-only-medium-group
rayCluster: ray-cluster-kuberay
app.kubernetes.io/name: kuberay
helm.sh/chart: ray-cluster-0.3.0
app.kubernetes.io/instance: ray-cluster
app.kubernetes.io/version: "1.0"
app.kubernetes.io/managed-by: Helm
- rayStartParams:
block: "true"
node-ip-address: "$MY_POD_IP"
redis-password: "LetMeInRay"
replicas: 1
minReplicas: 1
maxReplicas: 10
groupName: cpu-only-small-group
template:
spec:
imagePullSecrets:
- name: harbor-bybit
- name: harbor-infra
initContainers:
- name: init-myservice
image: busybox:1.28
command: ['sh', '-c', "until nslookup $RAY_IP.$(cat /var/run/secrets/kubernetes.io/serviceaccount/namespace).svc.cluster.local; do echo waiting for myservice; sleep 2; done"]
containers:
- volumeMounts:
- mountPath: /tmp/ray
name: log-volume
name: ray-worker
image: *********/bigdata/ray:prod-2.0.1-py38-ai2.0
imagePullPolicy: Always
resources:
limits:
cpu: 4
memory: 8Gi
requests:
cpu: 1
memory: 1Gi
env:
- name: TYPE
value: worker
- name: MY_POD_IP
valueFrom:
fieldRef:
fieldPath: status.podIP
- name: RAY_DISABLE_DOCKER_CPU_WARNING
value: "1"
- name: CPU_REQUEST
valueFrom:
resourceFieldRef:
containerName: ray-worker
resource: requests.cpu
- name: MY_POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: MLFLOW_TRACKING_URI
value: http://*******
- name: PLATFORM_ENV
value: test
- name: HDFS_CLUSTER_NAME
value: testcluster
ports:
- containerPort: 80
protocol: TCP
volumes:
- emptyDir: {}
name: log-volume
affinity:
{}
tolerations:
[]
nodeSelector:
{}
metadata:
annotations:
key: value
labels:
rayNodeType: worker
groupName: cpu-only-small-group
rayCluster: ray-cluster-kuberay
app.kubernetes.io/name: kuberay
helm.sh/chart: ray-cluster-0.3.0
app.kubernetes.io/instance: ray-cluster
app.kubernetes.io/version: "1.0"
app.kubernetes.io/managed-by: Helm
- rayStartParams:
block: "true"
node-ip-address: "$MY_POD_IP"
redis-password: "LetMeInRay"
replicas: 2
minReplicas: 2
maxReplicas: 2
groupName: workergroup
template:
spec:
imagePullSecrets:
- name: harbor-bybit
- name: harbor-infra
initContainers:
- name: init-myservice
image: busybox:1.28
command: ['sh', '-c', "until nslookup $RAY_IP.$(cat /var/run/secrets/kubernetes.io/serviceaccount/namespace).svc.cluster.local; do echo waiting for myservice; sleep 2; done"]
containers:
- volumeMounts:
- mountPath: /tmp/ray
name: log-volume
name: ray-worker
image:*******/bigdata/ray:prod-2.0.1-py38-ai2.0
imagePullPolicy: Always
resources:
limits:
cpu: 8
memory: 30Gi
nvidia.com/gpu: 1
requests:
cpu: 7
memory: 30Gi
nvidia.com/gpu: 1
env:
- name: TYPE
value: worker
- name: MY_POD_IP
valueFrom:
fieldRef:
fieldPath: status.podIP
- name: RAY_DISABLE_DOCKER_CPU_WARNING
value: "1"
- name: CPU_REQUEST
valueFrom:
resourceFieldRef:
containerName: ray-worker
resource: requests.cpu
- name: MY_POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.name
- name: MLFLOW_TRACKING_URI
value: http://****
- name: PLATFORM_ENV
value: prod
- name: HDFS_CLUSTER_NAME
value: victoria
ports:
- containerPort: 80
protocol: TCP
volumes:
- emptyDir: {}
name: log-volume
affinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- preference:
matchExpressions:
- key: instancetype
operator: In
values:
- g4dn.2xlarge
weight: 1
tolerations:
- effect: NoSchedule
key: instancetype
operator: Equal
value: g4dn.2xlarge
nodeSelector:
{}
metadata:
annotations:
key: value
labels:
rayNodeType: worker
groupName: workergroup
rayCluster: ray-cluster-kuberay
app.kubernetes.io/name: kuberay
helm.sh/chart: ray-cluster-0.3.0
app.kubernetes.io/instance: ray-cluster
app.kubernetes.io/version: "1.0"
app.kubernetes.io/managed-by: Helm
【补充】相关截图/链接/日志/监控等信息