
(小圆和小睿 generated by Midjourney)
本文讲述了ML system工程师“小圆”和计算框架工程师“小睿”在云原生环境下开发分布式系统的故事。本故事纯属虚构,旨在说明基于Ray开发分布式系统的简单性和易用性。
需求
小圆是一个ML system工程师,平时使用最多的编程语言是Python。最近主管交给他一个任务:“开发一个AutoML Service ,为公司的业务部门提供简单易用并高效的AutoML任务接入服务。”
拿到这个任务之后,小圆首先分析了需求,进行了系统设计:
- 整个服务需要一个入口,可以命名为**“proxy”** ,提供服务请求Request和服务结果查询Query接口;
- 我们提供一个**“client”** 方便用户集成,类似SDK,通过服务发现与“proxy”进行交互;
- 考虑到每个AutoML任务都会在runtime进行多节点并行计算,我们为每个任务分配一个**“trainer”** 进行协调和调度;
- 真正执行训练任务的是一个个**“worker”** 进程;
- 公司基础设施已经云原生化,所有组件的资源通过Kubernetes 进行弹性调度。
小圆还画了一张架构图,并在架构图中标记了整个系统的任务流:

小圆分析了整套分布式系统的特点:
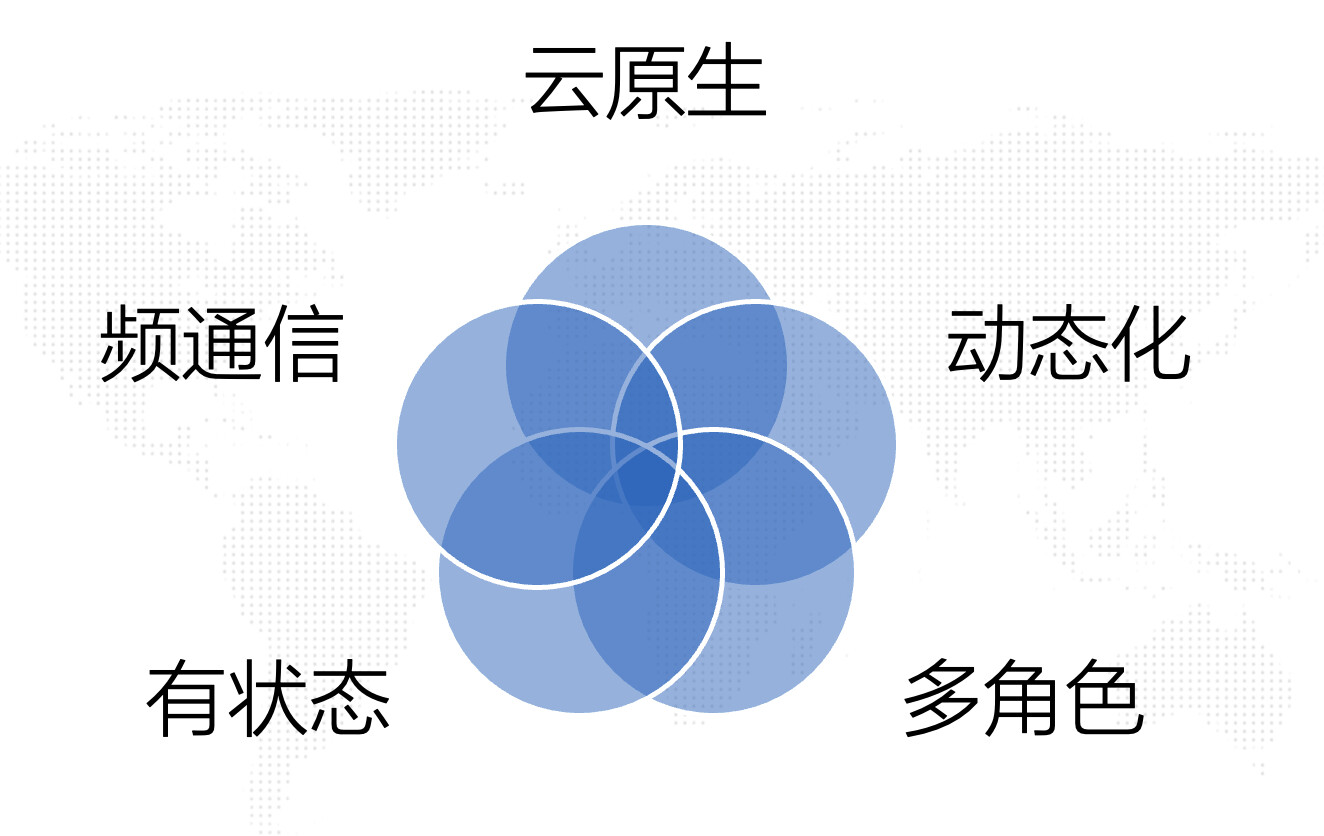
- 云原生 :整个系统云原生化,依赖K8S Pod的交付能力,资源弹性化;
- 动态化 :系统会在运行时进行大量资源的申请,资源申请规格和数量不固定;
- 多角色 :系统中角色较多,不同角色间通过不同的功能共同协作完成分布式任务;
- 有状态 :系统中存在多种有状态的角色;
- 频通信 :系统中不同角色或组件间需要频繁进行通信。
小圆在团队的架构会上分享了整个AutoML Service的架构设计,得到了团队同学的认可,主管对该架构也表示满意,小圆非常开心。主管问小圆AutoML Service什么时候能开发好,小圆信心满满,答应主管2周 时间内完成。
技术栈
接下来,小圆开始了为期2周的开发。他首先需要分析技术栈,选择一套合适的技术来完成整套分布式系统。他的思考过程如下:
- 要想实现整套分布式系统,首先需要实现一个个单点应用 。AutoML Service里的“proxy”、“trainer”和“worker”都可以看作独立的单点应用。考虑到自己最熟悉的编程语言是Python,小圆选择通过Python开发这些单点应用。
- 对于“proxy”和“trainer”来说,进程内部需要解决并发和异步IO 问题。小圆之前用过asyncio,对于Python协程的使用已经是轻车熟路了。
- 有了单体应用之后,小圆想到,接下来需要考虑组件间通信 的问题。小圆调研了一番发现,Protobuf+gRPC是非常主流的实现方式,所以选择了此方案。小圆之前虽然没有用过gRPC,但通过阅读官方tutorial,发现集成RPC框架并没有那么复杂,所以还是信心满满。另外小圆还想到系统间可能会传输一些Python的数据结构,如numpy,无法直接用Protobuf,需要引入Pickle做一层序列化。
- 接下来,小圆想到了另外一个问题:为了防止AutoML任务的结果数据丢失,是不是需要接入存储 系统?小圆听说隔壁团队经常通过RocksDB做本地的持久化存储,用HDFS做远程的持久化存储。但小圆没有接触过这些系统,有点无从下手。这时候小圆已经开始紧张起来了,他开始担心整体研发的工作量。
- 接下来的问题,更是让小圆陷入焦虑。小圆知道公司已经全面使用K8S ,但自己没有真正使用过,所以请教了主管,如何使用K8S部署AutoML Service。主管又分析了一下架构图,意味深长地说:“你看,你整个系统是高弹性的,并且是在运行时也会进行资源申请和释放,这就说明你的应用不仅需要初始化的时候通过kubectl进行部署,还需要在运行时与K8S apiserver进行频繁交互呀。我们最好用Operator 的形式,开发一个AutoML operator来做这件事情。” 小圆一脸懵,问到:“还要开发operator?但我没有写过Go呀!” 主管接着说:“Operator模式旨在记述(正在管理一个或一组服务的)运维人员的关键目标。 这些运维人员负责一些特定的应用和 Service…” 小圆越听越迷糊,跟主管说回去学习一下K8S再过来请教。
- 除了以上问题,小圆还想到要接入监控系统 。了解了下公司里其他应用都是使用Prometheus和Grafana两件套,小圆也决定采用此方案。
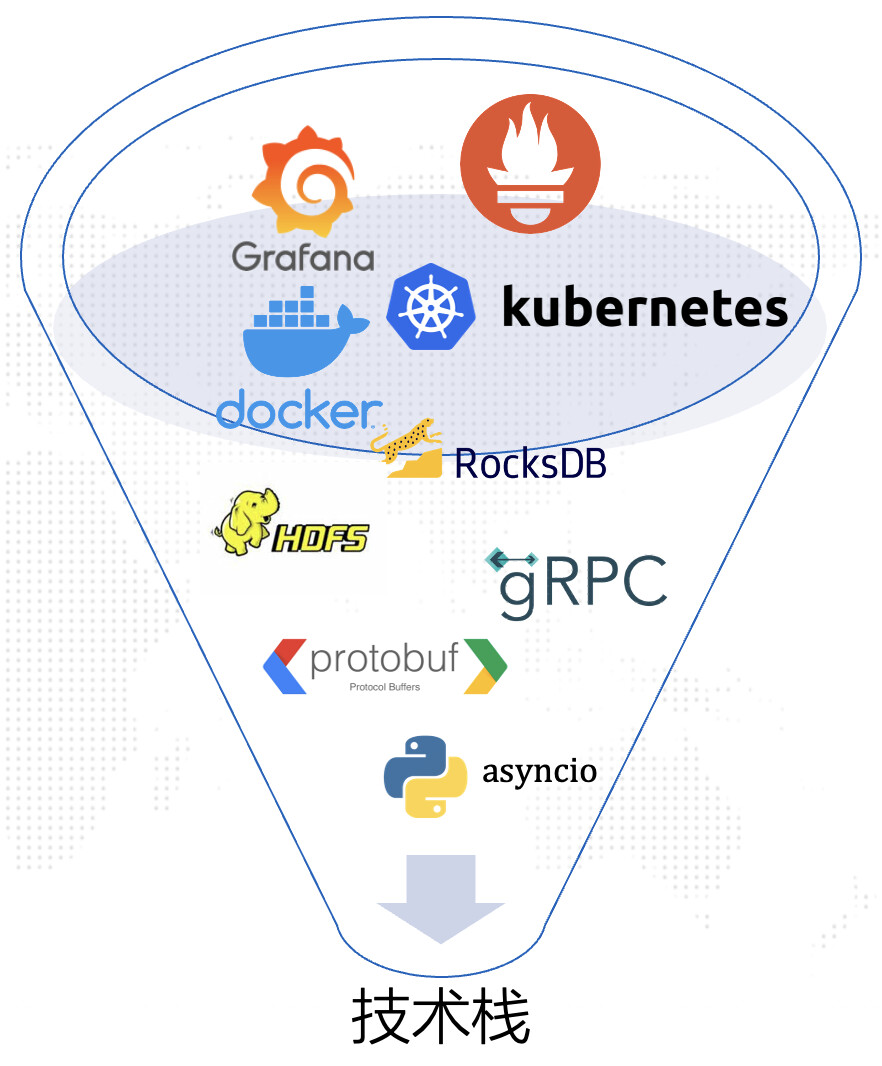
代码实现
技术栈选择好之后,小圆赶紧进入研发状态。从自己最熟悉的python代码开始开发,编写单体应用“proxy”,“trainer”,“worker”的内部逻辑,然后定义通信协议…
从编程语言的角度看,整个实现过程中,小圆至少需要编写以下5种语言的代码:
- Python:单体应用的核心开发语言,AutoML任务的处理、训练过程的实现等;
- Protobuf:定义“client”与“proxy”之间,“proxy”与“trainer”之间,“trainer”与“worker”之间的通信协议,然后通过codegen生成Python代码集成到应用内;
- Dockerfile:定制各个组件的运行时环境依赖,比如python3.9,训练需要的pip包依赖等;
- Go:AutoML operator的实现,CRD的定义,http弹性服务等;
- YAML:AutoML operator配置,AutoML Service初始化配置、弹性配置等。
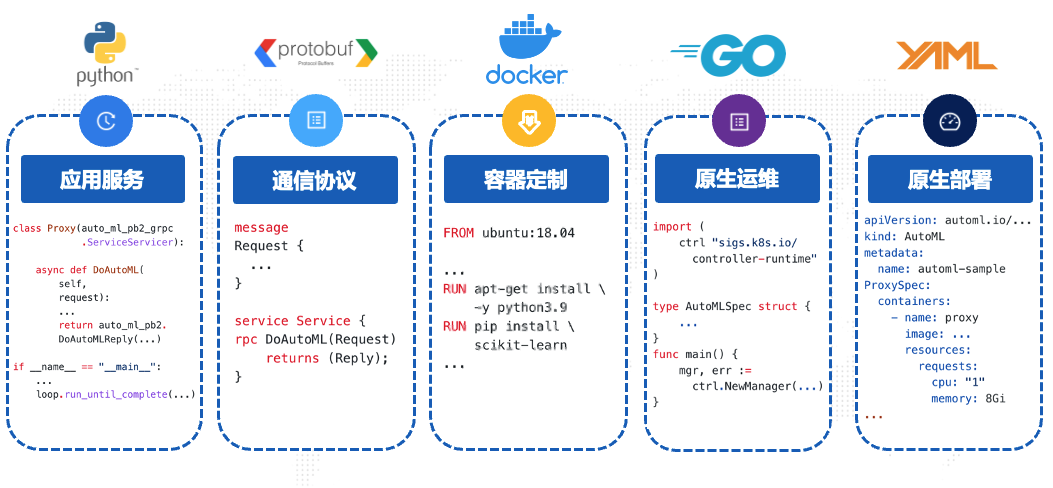
真正开发之后,小圆才意识到了是自己严重低估了系统的开发量和复杂度 ,眼看2周的时间马上就要到了,自己才刚刚开发完单体应用和通信过程,还在学习K8S相关基础知识。
转折
小圆非常极丧,又去找主管进行沟通,看看能不能把研发交付的时间延长1~2周。这时候,团队新入职的同学小睿 关注到了小圆的麻烦。小睿首先做了自我介绍:“我是一名计算框架工程师,在分布式计算方面有超过六年的研发经验。” 他向小圆了解了下情况,然后总结到:
“你要实现的是一个非常典型的分布式系统。其中包括一些分布式系统通用能力的构建,包括:组件通信、数据存储、部署、资源调度、故障恢复、运维与监控 等。这些通用问题非常常见,几乎所有的复杂分布式系统都会遇到。如果靠每个系统的研发团队自己去解决上述问题,那会消耗非常多的精力,并且往往最终的实现在效率和稳定性上很难保证。”
小圆似乎听懂了小睿的意思,问到:“那该怎么办呢?最佳实践是什么?”
小睿继续说道:“我们可以把这些分布式系统的通用问题交给Ray来解决 ,这样团队就可以把大部分的研发精力投入到真正的业务逻辑上啦!”
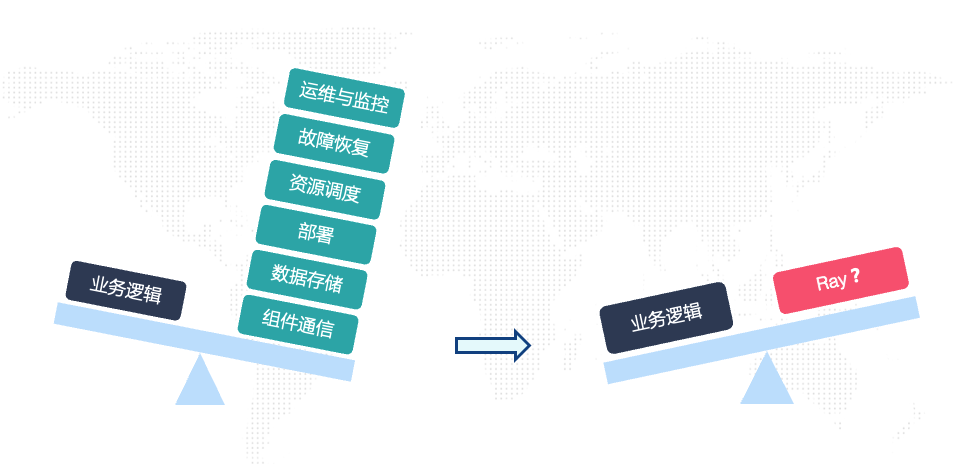
研发精力投入的转变
小圆追问到:“Ray?Ray是什么?好学吗?”
小睿回答到:“Ray的API非常简单,我给你大概讲一下你就明白啦!”
小睿开始介绍起来:

从历史上看,Ray是由加州大学伯克利分校RISELab在2017年发起的开源项目,开源以来取得了不错的活跃度,目前Contributors数量800+,Stars数25k+。
从功能上看,Ray是一个通用的分布式计算引擎 ,它的Core部分的主要设计思想是:“不绑定任何的计算模式,把单机编程中的基本概念进行分布式化 ”。具体来说,就是可以将单机编程中的Function映射成分布式系统中的Task,把单机编程中的Class映射成分布式系统中的Actor。它的接口非常的简单易用,如下:

分布式Task

分布式Actor
可以看出,Ray的分布式编程API并没有改变用户单机编程的习惯 ,仅仅通过简单的改动,就可以将单机程序改造成分布式程序。
小圆跟着小睿学习了Ray的接口之后,豁然开朗:“Ray中的Task是一种无状态计算单元 ,Actor是一种有状态计算单元 ,我可以这样理解吗?”
小睿肯定到:“非常正确!”
小圆继续说:“那我是不是可以通过Actor实现AutoML Service中的proxy和trainer,然后通过Task实现AutoML Service里的worker呢?”
小睿回答到:“可以的!开始开发吧!”
小圆重新绘制了架构图,在Kubernetes之上增加了Ray作为分布式底盘 ,然后通过Ray的Actor和Task实现相关的组件:
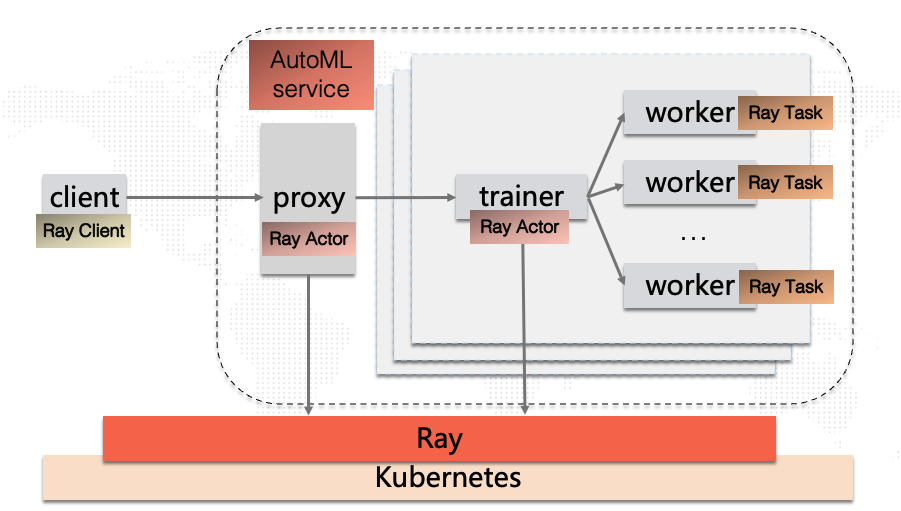
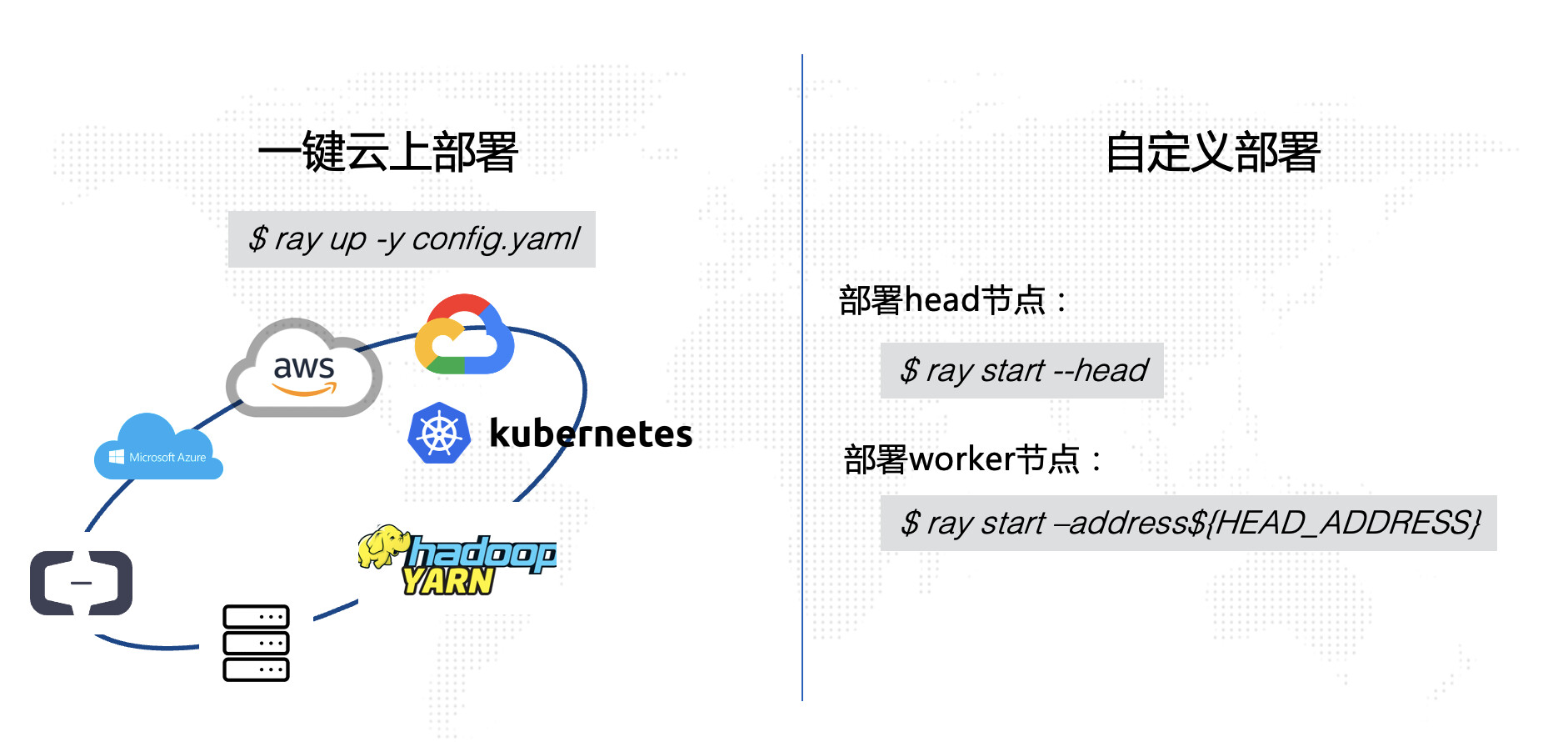
接下来,小圆和小睿首先在公司的Kubernetes环境部署了一个Ray集群。Ray集群的部署非常简单,可以通过Ray封装的命令行工具实现一键部署,部署平台除了Kubernetes,还可以选择各大主流云厂商:
然后就是具体的应用开发。根据架构图,我们从右向左开始实现。
首先实现**“worker”的逻辑** :定义一个单机可运行的Function,Function内部逻辑即通过训练集和测试集做一次训练和评估。可以通过@ray.remote将Function转换成Ray Task:
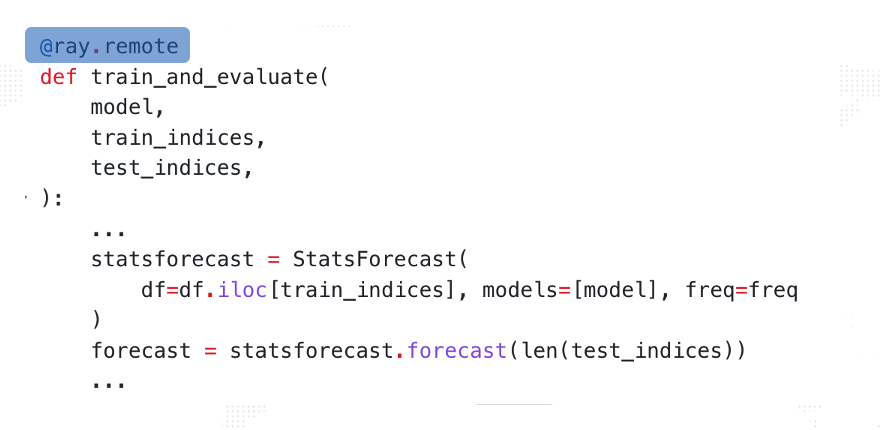
worker实现
然后实现**“trainer”的逻辑** :定义一个Trainer Class,其中成员函数train封装了对上述“worker”分布式Task的并发调用。通过@ray.remote将Class转换成Ray Actor:

trainer实现
然后实现**“proxy”的逻辑** :定义一个Proxy Class,其中成员函数do_auto_ml封装了对上述“trainer”分布式Actor按需部署与调用。同样通过@ray.remote将Class转换成Ray Actor:
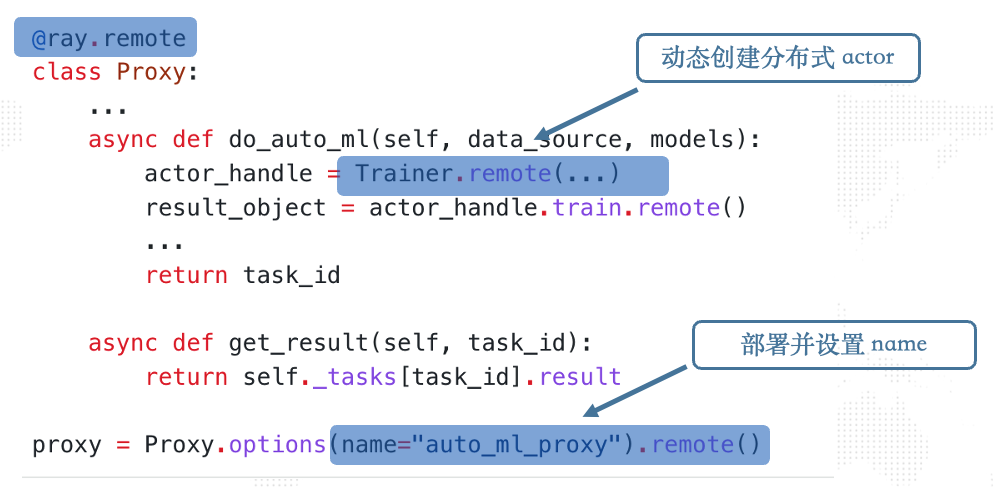
proxy实现
“client”的逻辑: “client”的主要交换对象是“proxy”。首先通过ray.get_actor对“proxy”进行服务发现,然后直接调用Actor的remote方法进行服务访问与结果查询:

client实现
至此,AutoML Service的全部流程开发完成!接下来我们看一些细节:
定制资源: AutoML Service中的每个单点应用可能会有差异化的资源定制需求,比如“worker”需要进行训练,可能会用到GPU;而“proxy”和“trainer”更多的是控制逻辑,分配相应的CPU即可。这部分的需求在云原生环境下是通过Yaml文件指定的,而在Ray中更为简单灵活,直接在代码中指定即可。小圆通过Ray的资源定制接口为每个组件设置了相应的资源:
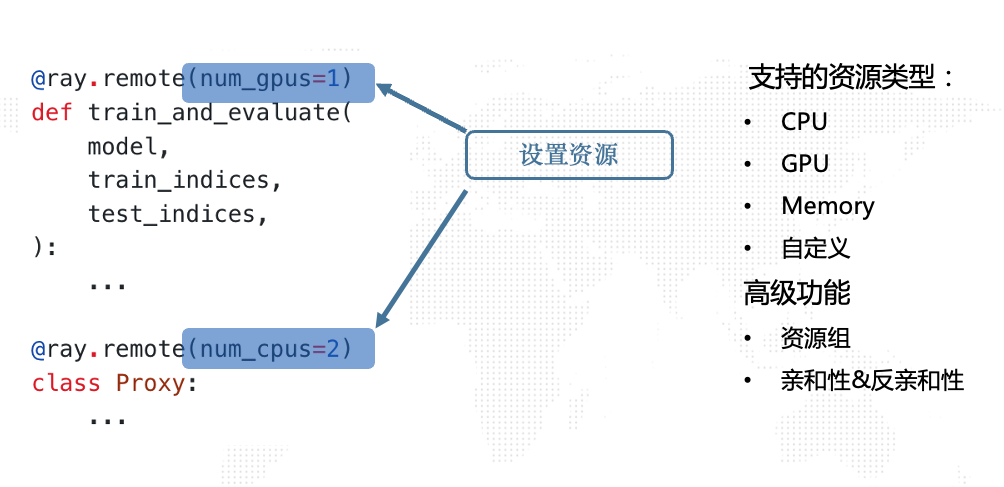
定制资源
环境依赖: 同样的,AutoML Service的每个单点应用可能会有差异化的环境定制需求。Ray中的运行时环境定制接口非常灵活,插件也非常丰富,可以满足不同维度、不同语言和不同场景的运行时环境要求。小圆通过runtime env接口为不同的单点应用定制环境,如“worker”,需要python3.9和一些pip包依赖:
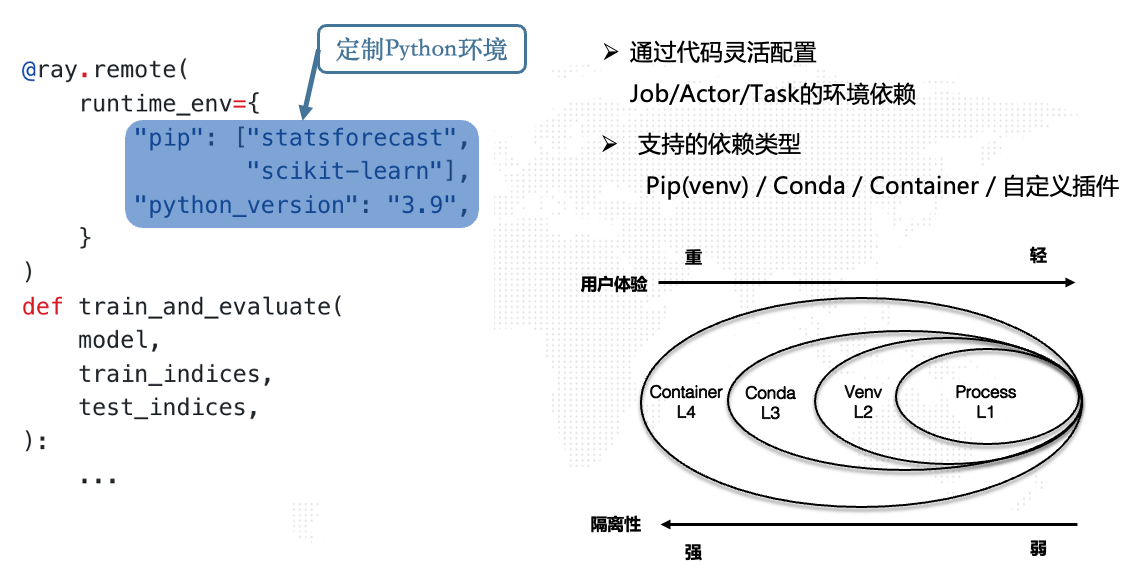
环境定制
运维与监控: 最后,小圆通过Ray Dashboard观察了整个分布式系统的运行情况和日志,并且通过内置的Metrics接口和Grafana大盘对系统指标进行监控:
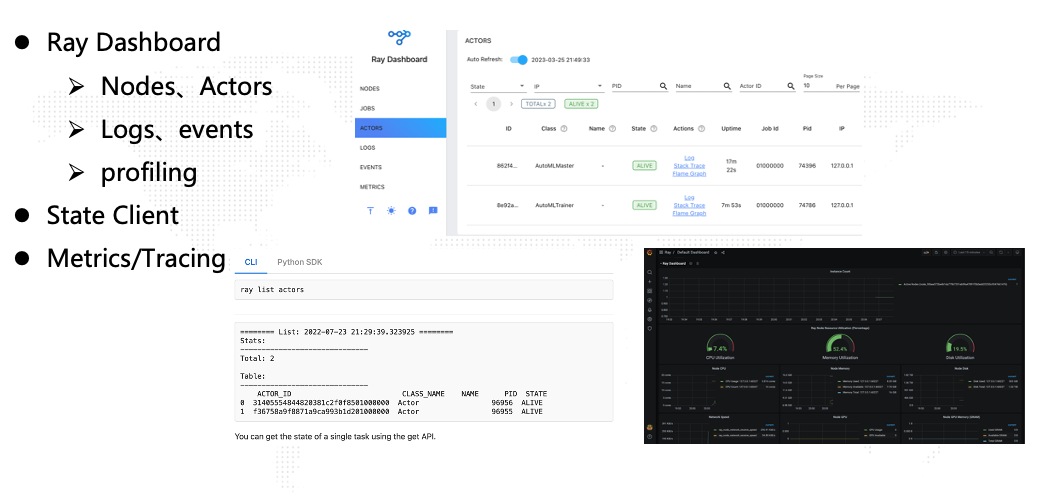
运维与监控
至此,小圆已经完成了AutoML Service初版的开发。令他震惊的是,整个开发仅耗时2天 !更为令他震惊的是,整个应用仅不到300行代码 !
小圆非常激动,真正体会到了基于Ray开发分布式系统的简单性和易用性 ,他非常感谢小睿的帮助。
总结
事后,小圆和小睿做了一个实验。他们一起将小圆之前通过原生方式开发的版本进行了完善,最终也形成了一个可以跑的版本。他们对两种方式进行了对比 :
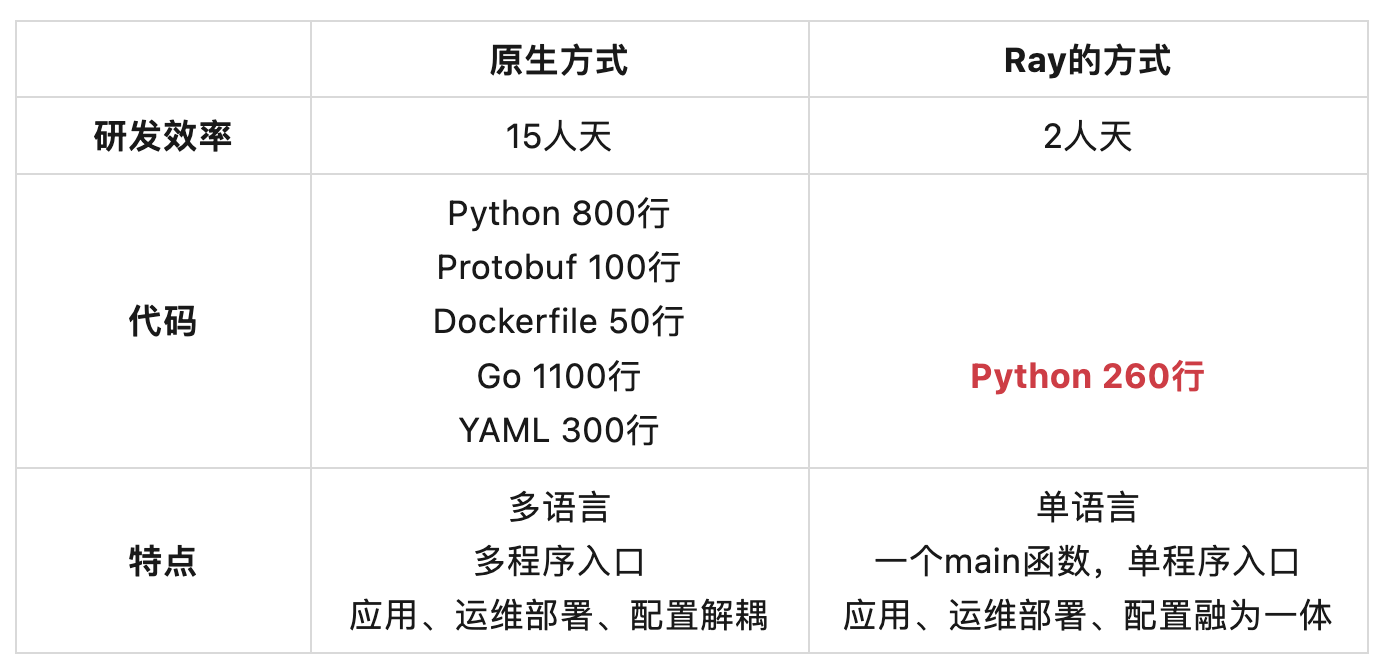
两种实现方式的Demo地址 :
- 原生方式实现代码:ray-python-example/automl_service/cloud_native at main · SongGuyang/ray-python-example · GitHub
- Ray方式实现代码:https://github.com/SongGuyang/ray-python-example/tree/main/automl_service/ray
备注:
研发效率中的人天数据包含相关技术的学习时间。
此Demo中的实现并没有包含Fault tolerance功能,期待后续更新。