
引言
随着互联网数据的爆发式增长,互联网业务的发展速度已经明显高于计算机硬件的发展速度。在此背景下,我们可以看到仅靠单机系统能解决的问题越来越少,而越来越多的领域和应用场景需要构建分布式系统。C++作为native的编程语言,由于其高性能、轻量级的特点广泛应用于现代分布式系统中,如Tensorflow、Caffe、XGboost、Redis等都选择C/C++作为主要的编程语言。
相比单机应用,想要构建一个功能完善、高可用、可应用于生产环境的C++分布式系统并没有那么简单。通常我们需要做以下考虑:
- 解决通信问题。我们通过protobuf等序列化工具定义组件间的通信协议,然后通过RPC框架(或者socket)实现通信。这里面还需要考虑服务发现、同/异步IO和多路复用等问题,整个实现较为繁琐。
- 解决部署问题。我们需要找到满足特定资源规格的服务器,对不同组件的进程进行部署。这个过程可能需要对接不同的云平台实现资源调度。
- 解决故障恢复问题。监控任意一个节点的故障事件,重启并恢复系统状态。
看起来,整个实现中需要考虑的问题非常多,完成所有这些事情并不容易。那么有没有一个系统,能够帮你解决以上所有的分布式问题,让你能够专注在系统本身的逻辑上呢?随着Ray的到来,理想即将成为现实。
Ray是什么
整体介绍
Ray(https://github.com/ray-project/ray)是一个简单、通用的分布式计算框架。项目最初由加州大学伯克利分校RISELab发起并开源。在过去的几年中,Ray项目发展迅速,在蚂蚁集团、Intel、微软、AWS、Uber等公司被广泛应用于构建各种AI、大数据系统,并且已经形成了较为完善的生态圈(Tune、Rlib、Serve、分布式Scikit-learn、XGboost on Ray等)。相比现有的大数据计算系统(Spark、Flink等),Ray最本质的特点和不同点在于,Ray的设计没有基于某种特定的计算范式(例如DataStream、DataSet),而是回归编程本身,通过抽象编程中最基本的Function和Class等概念,构建了一套简单易用的分布式编程API。所以从系统层次的角度看,Ray的API更加底层,更加灵活。Ray不会限制你的应用场景,无论是批处理、流计算、图计算,还是机器学习、科学计算等,只要你的系统具有分布式特性,需要利用多机协同完成一个特定的任务,你就可以选择Ray帮你完成分布式系统的构建。
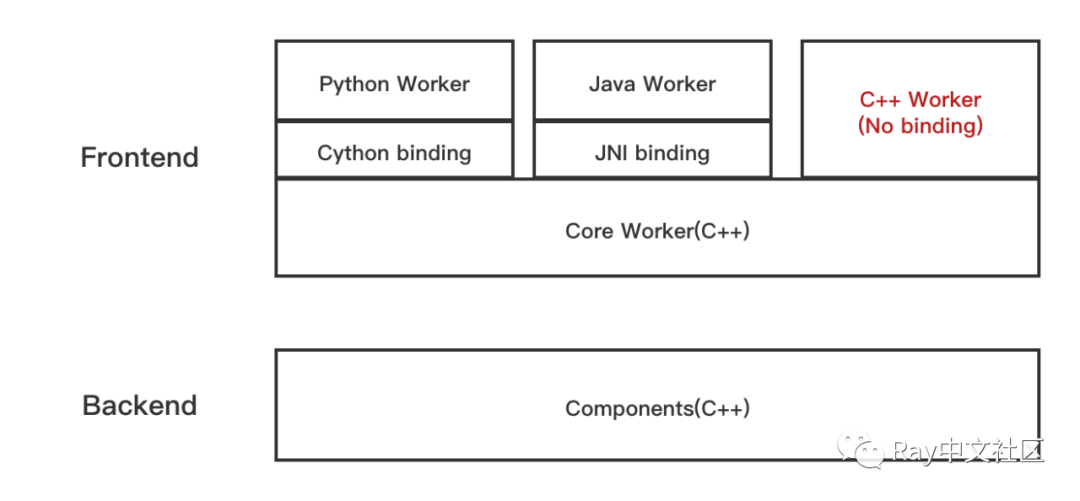
C++ API
Ray在创建初期只支持Python API,2018年中旬蚂蚁集团开源了Java API。本文介绍的C++ API是Ray上用户接口的第三种语言实现。有人会问,已经有了Python语言和Java语言的支持,为什么还要开发C++版本?我们开发C++ API的主要原因是,在某些高性能场景,Java和Python在系统调优之后仍然无法满足业务需求。除此之外,Ray底层内核和组件本身就是纯C++实现,使用C++ API会让用户层和内核层无缝衔接,整个系统无语言间调用开销。
下面简要介绍一下Ray C++ API中几个核心概念和使用方式。
Task
Ray中的Task对应单机编程中的function。通过Ray的Task API,我们可以很容易地把任意一个C++函数放到分布式集群中异步执行,大幅提高执行效率。
假设我们有一个耗时的heavy_compute函数,如果在单机环境中串行执行10000次,整体耗时很长:
int heavy_compute(int value) {
return value;
}
std::vector<int> results;
for(int i = 0; i < 10000; i++) {
results.push_back(heavy_compute(i));
}
利用Ray将单机的heavy_compute改造成分布式的heavy_compute:
// 声明heavy_compute为remote function
RAY_REMOTE(heavy_compute);
std::vector<ray::ObjectRef<int>> results;
for(int i = 0; i < 10000; i++) {
// 利用ray::Task调用远程函数,它们被Ray自动调度到集群的节点上实现分布式计算
results.push_back(ray::Task(heavy_compute).Remote(i));
}
// 获取分布式计算的结果
for(auto result : ray::Get(results)) {
std::cout<< *result << std::endl;
}
Actor
普通的Task是一种无状态的计算,如果想实现有状态的计算,需要使用Actor。
Actor对应单机编程中的Class。基于Ray强大的分布式能力,我们可以将以下的单机Counter改造成部署在远程节点的分布式Counter。
class Counter {
int count;
public:
Counter(int init) { count = init; }
int Add(int x) { return x + 1; }
};
Counter *CreateCounter(int init) {
return new Counter(init);
}
RAY_REMOTE(CreateCounter, &Counter::Add);
// 创建一个Counter actor
ActorHandle<Counter> actor = ray::Actor(CreateCounter).Remote(0);
// 调用actor的远程函数
auto result = actor.Task(&Counter::Add).Remote(1);
EXPECT_EQ(1, *(ray::Get(result)));
Object
在以上Task和Actor的例子中,我们注意到,最后都是使用“ray::Get”获取计算结果。这里绕不开的一个概念就是Object。每次调用“Remote”方法返回的是一个Object引用(ObjectRef),每个ObjectRef指向一个集群内唯一的远程Object。Ray的Object类似异步编程中常见的future概念。在Ray中,Object会存储在底层的分布式Object Store中(基于shared memory)。当你调用“ray::Get”方法获取一个Object时,会从远程节点拉取数据到当前节点,经过反序列化返回到你的程序中。
除了存储应用的中间计算结果,你也可以通过“ray::Put”创建一个Object。除此之外,你也可以通过“ray::Wait”接口等待一组Object的结果。
// 把一个object Put到object store中
auto obj_ref1 = ray::Put(100);
// 从object store获取数据
auto res1 = obj_ref1.Get();
//或者调用ray::Get(obj_ref1)
EXPECT_EQ(100, *res1);
// 等待多个object ready
auto obj_ref2 = ray::Put(200);
ray::Wait({obj_ref1, obj_ref2}, /*num_results=*/1, /*timeout_ms=*/1000);
从以上基础API可以看出,Ray已经解决了分布式系统组件间通信、存储和传输等问题。Ray还有一些高级功能用来解决分布式系统中的其他问题,例如调度、故障恢复、部署运维等,具体的将在下面的例子中进行介绍。
用Ray C++实现分布式存储系统
简单了解了Ray的定位和Ray C++ API后,让我们用一个实际的例子看一下如何利用Ray C++ API,构建一个简单的KV存储系统。
demo说明
在这个简单的KV存储系统中,有一个main server和一个backup server,仅main server提供服务,backup server则只用于备份数据,不提供服务。同时要求系统具备自动故障恢复能力,即任意一个server重启后数据不会丢失,能继续提供服务。
注 :这只是一个demo,不专注存储本身的逻辑和优化,目的是使用尽可能简单的代码来展示如何用Ray来快速开发一个分布式存储系统。完整代码请在文末点击“阅读原文”查看。
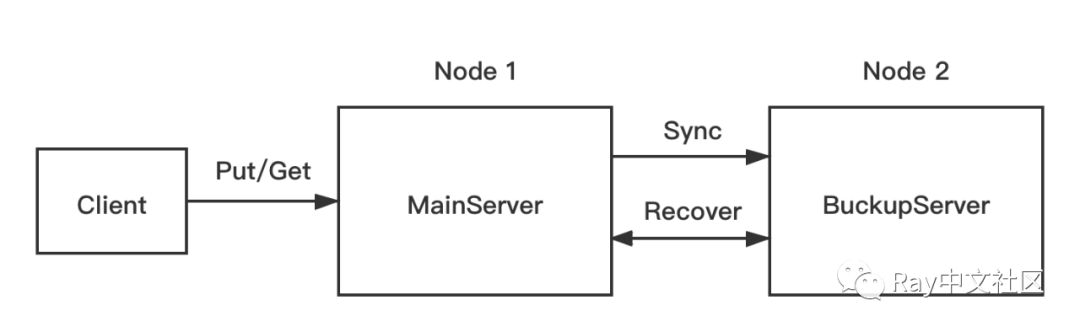
Server实现
用C++ API实现一个分布式存储比较简单,用户可以先按照单机版的KV store的思路去写server,稍后再利用Ray的分布式部署和调度能力将单机版的KV store变成一个分布式的KV store。
main server
class MainServer {
public:
MainServer();
std::pair<bool, std::string> Get(const std::string &key);
void Put(const std::string &key, const std::string &val);
private:
std::unordered_map<std::string, std::string> data_;
};
std::pair<bool, std::string> MainServer::Get(const std::string &key) {
auto it = data_.find(key);
if (it == data_.end()) {
return std::pair<bool, std::string>{};
}
return {true, it->second};
}
void MainServer::Put(const std::string &key, const std::string &val) {
// 先将数据同步到backup server
...
// 再更新本地kv
data_[key] = val;
}
可以看到分布式KV store的读数据(MainServer::Get)的实现和单机版的实现相比没有任何差异,用户不必关心分布式的细节,关注业务逻辑本身即可。Put时要注意先将数据同步写到backup server中再写本地,确保数据的一致性。
backup server
class BackupServer {
public:
BackupServer();
// 当main server重启时会调用GetAllData做数据恢复
std::unordered_map<std::string, std::string> GetAllData() {
return data_;
}
// 当main server写数据时会调用SyncData将数据先同步到buckup server
void SyncData(const std::string &key, const std::string &val) {
data_[key] = val;
}
private:
std::unordered_map<std::string, std::string> data_;
};
部署
集群部署
部署应用之前需要首先部署一个Ray集群。目前Ray已经支持在多个主流云平台进行一键部署,如AWS、Azure、GCP、Aliyun和Kubernetes环境等。如果你已经拥有了一个配置文件,可以在安装Ray之后通过命令行进行一键部署:
ray up -y config.yaml
具体如何配置可以参考官方文档。
另外一种选择,如果你拥有正在运行的服务器,也可以通过在各服务器上执行start命令手动组建Ray集群:
- 选择一台服务器作为主节点:
ray start --head
- 在其他服务器加入主节点进行组网:
ray start --address=${HRAD_ADDRESS}
actor部署
Ray集群部署之后,我们需要将前面创建的MainServer和BackupServer这两个actor实例部署到集群中,以提供分布式存储服务。用Ray创建Actor的API就可以很简单的实现actor部署。
static MainServer *CreateMainServer() { return new MainServer(); }
static BackupServer *CreateBackupServer() { return new BackupServer(); }
// 声明remote function
RAY_REMOTE(CreateMainServer, CreateBackupServer);
const std::string MAIN_SERVER_NAME = "main_actor";
const std::string BACKUP_SERVER_NAME = "backup_actor";
// 通过ray::Actor将actor的实例部署到Ray集群中
void StartServer() {
ray::Actor(CreateMainServer)
.SetName(MAIN_SERVER_NAME)
.Remote();
ray::Actor(CreateBackupServer)
.SetName(BACKUP_SERVER_NAME)
.Remote();
}
调度
设置资源
如果你对actor运行环境的硬件有特殊要求,还可以通过API设置actor所需要的资源,比如CPU,内存等资源。
// 所需资源cpu:1, 内存1G
const std::unordered_map<std::string, double> RESOUECES{
{"CPU", 1.0}, {"memory", 1024.0 * 1024.0 * 1024.0}};
// 通过ray::Actor将actor的实例部署到Ray集群中并设置资源需求
void StartServer() {
ray::Actor(CreateMainServer)
.SetName(MAIN_SERVER_NAME)
.SetResources(RESOUECES) //设置资源
.Remote();
ray::Actor(CreateBackupServer)
.SetName(BACKUP_SERVER_NAME)
.SetResources(RESOUECES) //设置资源
.Remote();
}
设置调度策略
我们希望将main server和backup server两个actor调度到不同的节点上,以保证某一个节点挂掉不会同时影响两个server。可以利用Ray的Placement Group实现这种特殊的调度功能。
Placement Group允许用户从集群中预置一部分资源供Task和Actor调度。
ray::PlacementGroup CreateSimplePlacementGroup(const std::string &name) {
// 设置Placement Group的资源
std::vector<std::unordered_map<std::string, double>> bundles{RESOUECES, RESOUECES};
// 创建Placement Group并设置调度策略为平铺调度(SPREAD)
ray::PlacementGroupCreationOptions options{
false, name, bundles, ray::PlacementStrategy::SPREAD};
return ray::CreatePlacementGroup(options);
}
auto placement_group = CreateSimplePlacementGroup("my_placement_group");
assert(placement_group.Wait(10));
上面的代码创建了一个Placement Group,调度策略为平铺(SPREAD), 平铺调度的含义是将actor以平铺的方式调度到不同的节点上。更多的调度策略可以参考Ray的官方文档 https://docs.ray.io/en/master/placement-group.html。
接下来就可以通过Placement Group将actor调度到不同的节点上了。
// 通过ray::Actor将actor的实例调度到Ray集群不同的节点上
void StartServer() {
// 调度main server
ray::Actor(CreateMainServer)
.SetName(MAIN_SERVER_NAME)
.SetResources(RESOUECES)
.SetPlacementGroup(placement_group, 0) //调度到某个节点上
.Remote();
// 调度backup server
ray::Actor(CreateBackupServer)
.SetName(BACKUP_SERVER_NAME)
.SetResources(RESOUECES)
.SetPlacementGroup(placement_group, 1) //调度到某个节点上
.Remote();
}
服务发现和组件通信
现在我们已经把main server和backup server两个actor实例部署到Ray集群中的两个节点上了,接下来需要解决main server的服务发现问题和client-server的通信问题。
Ray的named actor可以很方便的实现服务发现,我们在创建actor的时候设置了actor的名字,后续就可以通过ray::GetActor(name)来发现之前创建的actor了。
Ray Task则可以解决client-server之间的通信问题,就像调用本地函数一样实现远程函数调用,用户无需关心数据通信的细节(如传输协议、网络通信等)。
class Client {
public:
Client() {
// main server服务发现
main_actor_ = ray::GetActor<MainServer>(MAIN_SERVER_NAME);
}
bool Put(const std::string &key, const std::string &val) {
// 利用Ray Task调用远端main server的Put函数
(*main_actor_).Task(&MainServer::Put).Remote(key, val).Get();
return true;
}
std::pair<bool, std::string> Get(const std::string &key) {
// 利用Ray Task调用远端main server的Get函数
return *(*main_actor_).Task(&MainServer::Get).Remote(key).Get();
}
private:
boost::optional<ray::ActorHandle<MainServer>> main_actor_;
};
故障恢复
进程故障恢复
Ray提供了进程故障恢复的功能,比如actor进程挂掉之后Ray会自动将actor进程拉起来,并重新创建actor实例,只需要设置actor的最大重启次数即可。
// 通过ray::Actor将actor的实例调度到Ray集群不同的节点上并设置最大重启次数
void StartServer() {
ray::Actor(CreateMainServer)
.SetName("main_actor")
.SetResources(RESOUECES)
.SetPlacementGroup(placement_group, 0)
.SetMaxRestarts(1) //设置最大重启次数让Ray做自动故障恢复
.Remote();
ray::Actor(CreateBackupServer)
.SetName("backup_actor")
.SetResources(RESOUECES)
.SetPlacementGroup(placement_group, 1)
.SetMaxRestarts(1) //设置最大重启次数让Ray做自动故障恢复
.Remote();
}
状态恢复
虽然Ray会做进程故障恢复,重新创建actor实例,但是actor的运行状态需要用户去做状态恢复处理,比如main actor挂掉之后重新拉起来,之前在main actor内存中的数据都会丢失,需要做数据恢复。
MainServer::MainServer() {
// 如果当前实例是重启的则做故障处理
if (ray::WasCurrentActorRestarted()) {
HandleFailover();
}
}
void MainServer::HandleFailover() {
backup_actor_ = *ray::GetActor<BackupServer>(BACKUP_SERVER_NAME);
// 从backup server拉取所有数据
data_ = *backup_actor_.Task(&BackupServer::GetAllData).Remote().Get();
RAYLOG(INFO) << "MainServer get all data from BackupServer";
}
main server的failover是在构造函数里面做的,Ray提供了判断actor实例是否重启的API。在actor的构造函数中如果发现是重启的实例则做数据恢复的处理,具体方法就是从backup server拉取所有数据。backup server的failover处理也是类似的, 不再赘述。
运维与监控
Ray提供了一套简单的运维和监控系统(Dashboard)让我们可以实时查看系统的运行情况。
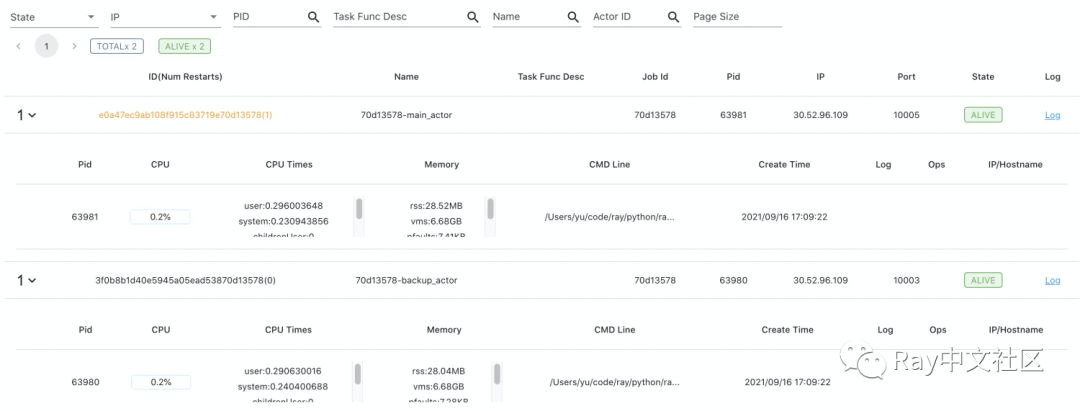
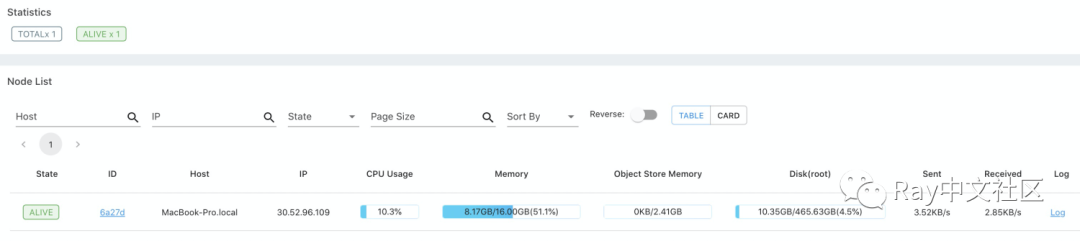
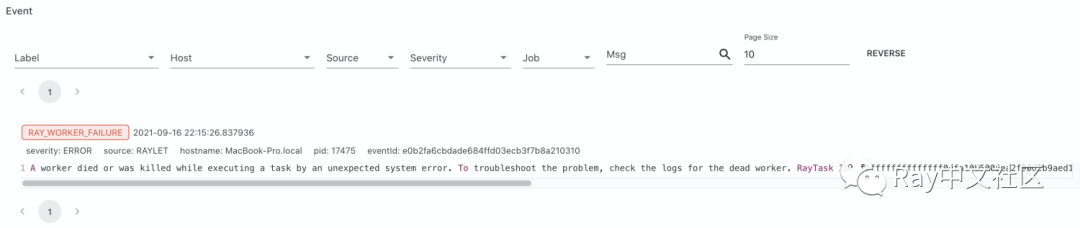
以上面的KV store为例,我们可以看到actor列表、node列表和运行日志等信息,并且可以捕捉到一些异常的events。
actor列表
node列表
运行日志
异常events透出
如何快速开始
Ray目前已经完成了1.7.0版本的release,C++ API作为其中一个highlight功能正式集成到wheel包发布,详见发布记录https://github.com/ray-project/ray/releases/tag/ray-1.7.0。
考虑到Ray内核的实现是多语言的,跑C++应用需要同时具备Python环境和C++环境,我们将Ray整体打包成wheel用pip进行管理。你可以通过以下方式快速获取一个Ray C++模版工程。
环境要求:Linux系统或macOS, Python 3.6-3.9版本,C++17环境,bazel 3.4以上版本(可选,模版工程基于bazel)。
- 安装最新版本的Ray:
pip install -U ray[cpp]
- 通过ray命令行工具生成C++模版工程:
mkdir ray-template && ray cpp --generate-bazel-project-template-to ray-template
- 进入模版工程,编译并运行:
cd ray-template && sh run.sh
以上运行方式会在跑example的过程中在本地拉起Ray集群,example运行结束后自动关闭Ray集群。如果你想让应用连接已有的Ray集群,可以按如下方式启动:
ray start --head
RAY_ADDRESS=127.0.0.1:6379 sh run.sh
测试结束后可以通过stop命令关闭ray集群,避免残留进程:
ray stop
现在,你可以开始基于模版工程开发自己的C++分布式系统了!
总结
本文通过一个存储系统的例子介绍了如何利用Ray C++ API构建分布式系统,整个demo代码不过200多行,却同时解决了部署、调度、通信、故障恢复和运维监控等问题。我们可以发现,Ray致力于解决分布式系统的通用问题,不限制你的计算范式和应用场景,无论是针对新建应用还是已有的应用,都可以通过Ray快速升级为强大的分布式系统。
联系我们
了解更多细节,请阅读 Ray官方文档 https://docs.ray.io/en/master/index.html。
贡献代码,可以直接提PR到 https://github.com/ray-project/ray,或者给我们提issue。
您也可以通过slack联系我们,加入Ray的channel。
微信公众号:搜索并关注“Ray中文社区”。
关于我们
我们是蚂蚁计算智能技术部团队,横跨美国硅谷、中国北京、上海、杭州和成都。我们追求的工程师文化是开放、简单、迭代、追求效率、用技术解决问题!热情相邀加入我们!!
请联系我们的邮箱:antcomputing@antgroup.com
原文由 宋顾杨 祁宇于2021年10月12日发表于Ray中文社区公众号,查看原文