随着Ray Summit的召开,第二个大版本2.0正式和大家见面了,这标志着Ray已经向自己的目标更进了一步:使分布式计算变得更易于扩展、更加统一和更加开放。

为了达成这样的目标,Ray 2.0重点构建了整合ML生态的能力,提供了一套更易用的工具集给ML开发者。
整合ML生态
Ray AI Runtime :一个可扩展和统一的ML工具集
从诞生以来,Ray一直被用来加速和扩展ML任务。本次Beta发布的Ray AI Runtime(AIR),是通过与社区用户的沟通,考虑不同大小规模的使用场景,总结多年的经验教训后产生的一套简单、统一的工具集。
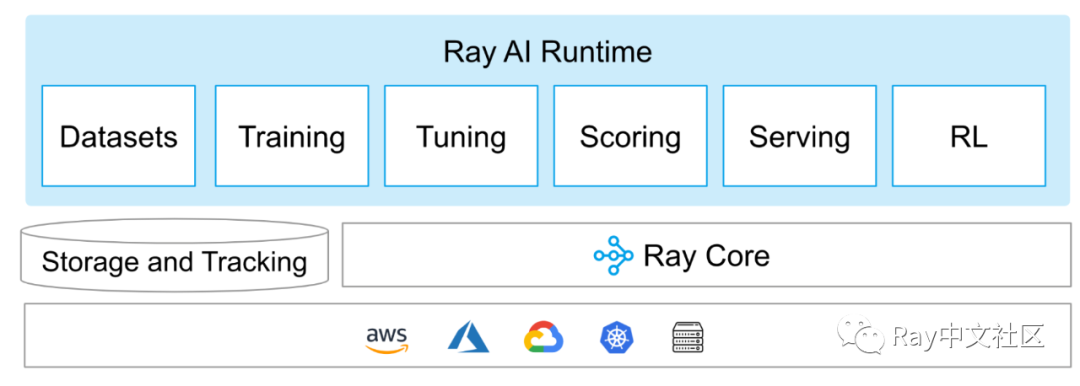
通过AIR,我们可以很方便地集成Ray原生的ML库和社区中常用的ML框架(如Pytorch、Tensorflow等)。用户只需要写少量的python代码,就可以很容地运行各种类型的ML任务,而底层复杂的规模化协同计算由Ray来完成。
大规模shuffle支持
近期,越来越多的ML用户需要Ray的大数据shuffle能力,他们想通过Ray原生的shuffle能力统一自己的ML架构。因此在Ray 2.0中,我们通过Ray Datasets实现了100TB 数据的shuffle。更新细节可以参考文档和论文 https://arxiv.org/abs/2203.05072。
生产化能力
KubeRay
KubeRay由字节、蚂蚁、微软等公司联合开发,可以帮助用户在K8S上很方便地部署基于Ray的作业和服务,可以完美替代之前的Python Ray operator。KubeRay在2.0版本中处于Beta发布阶段,是目前官方推荐的Ray on K8S最佳方式。
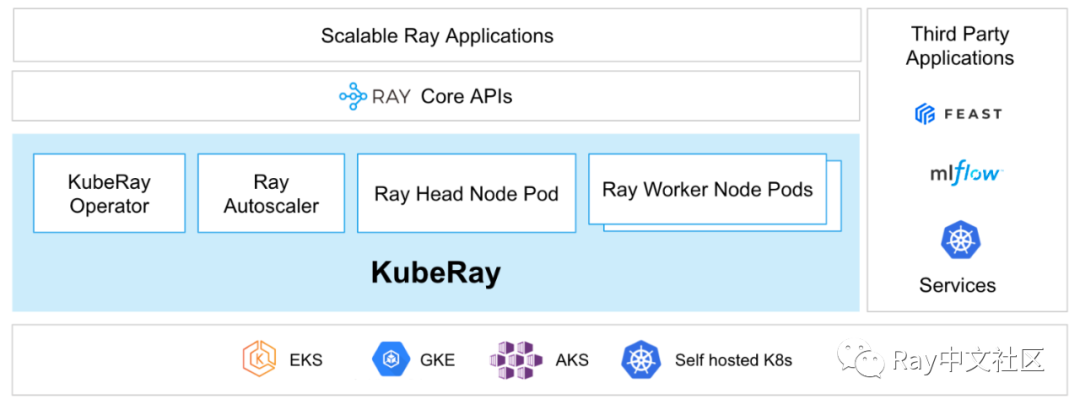
高可用能力
利用KubeRay,我们可以很方便地部署一个Ray Serve集群。你可以用“fail-over”模式部署services,或者用“fully HA”模式部署Ray cluster。在此模式下,任何的单点故障都不会影响Ray集群的可用性。
可观察性(Observability)工具
在运维Ray集群过程中,你是否曾经想要查看集群和作业的运行状态?在2.0中,Ray提供了一套全新的API帮助开发者查看Ray的运行状态,包括健康状态、实例、性能数据等。这套API目前处于Alpha阶段。
原生库API增强
Ray Serve Deployment Graph
多模推理已经成为现代ML应用中一种常见的方式,而Ray Serve灵活的部署与执行方式也一直很适合支撑类似的场景。
基于Ray Serve的优势,Ray 2.0提供了一种新的方式来构建、测试和部署多模推理graph,即Deployment Graph API。Deployment Graphs建立在Ray task和actor API之上,可以用来构建多模推理pipeline,而ML用户可以在其中混合模型和自己的业务逻辑。
RLlib优化
在Ray 2.0中,RLlib团队重构了所有关键算法的实现,使其更容易实现新算法或对现有算法进行调整。
本次发布中,RLlib 引入了一个新的Connectors API。该API可以使环境和策略模型的预处理阶段对用户更加明确和透明,简化了RLlib模型的部署。
除此之外,RLib还新增了一些算法和功能,如Critic Regularized Regression (CRR)等。