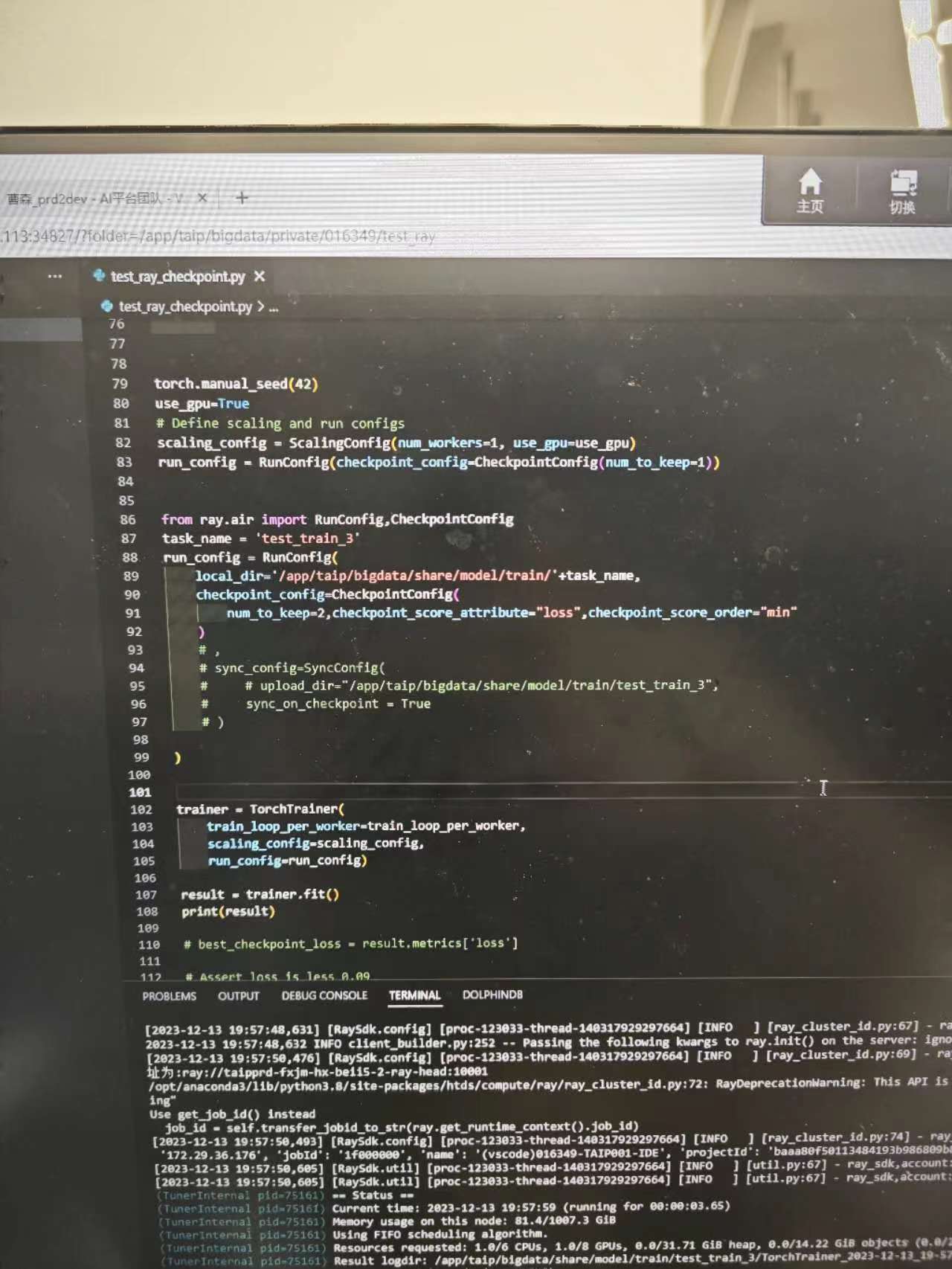
1.通过kuberay创建ray集群。
2.集群配置:
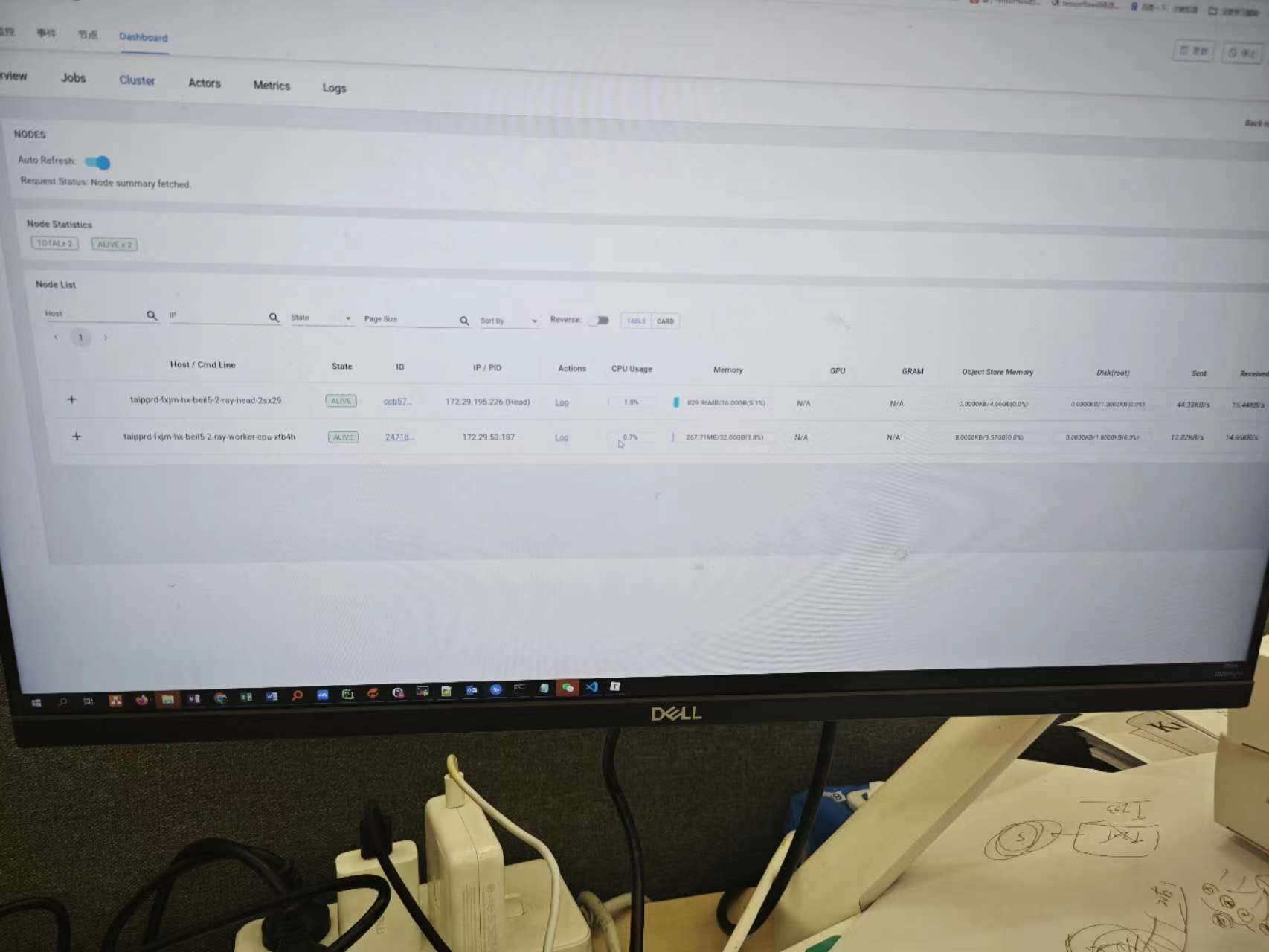
是个弹性伸缩的ray集群,有两种类型的节点,cpu类型的和gpu类型的。
head 4C 8G
group-worker1: 8C 32G min=1, max=4
group-worker2: 8C 32G min=0, max=2
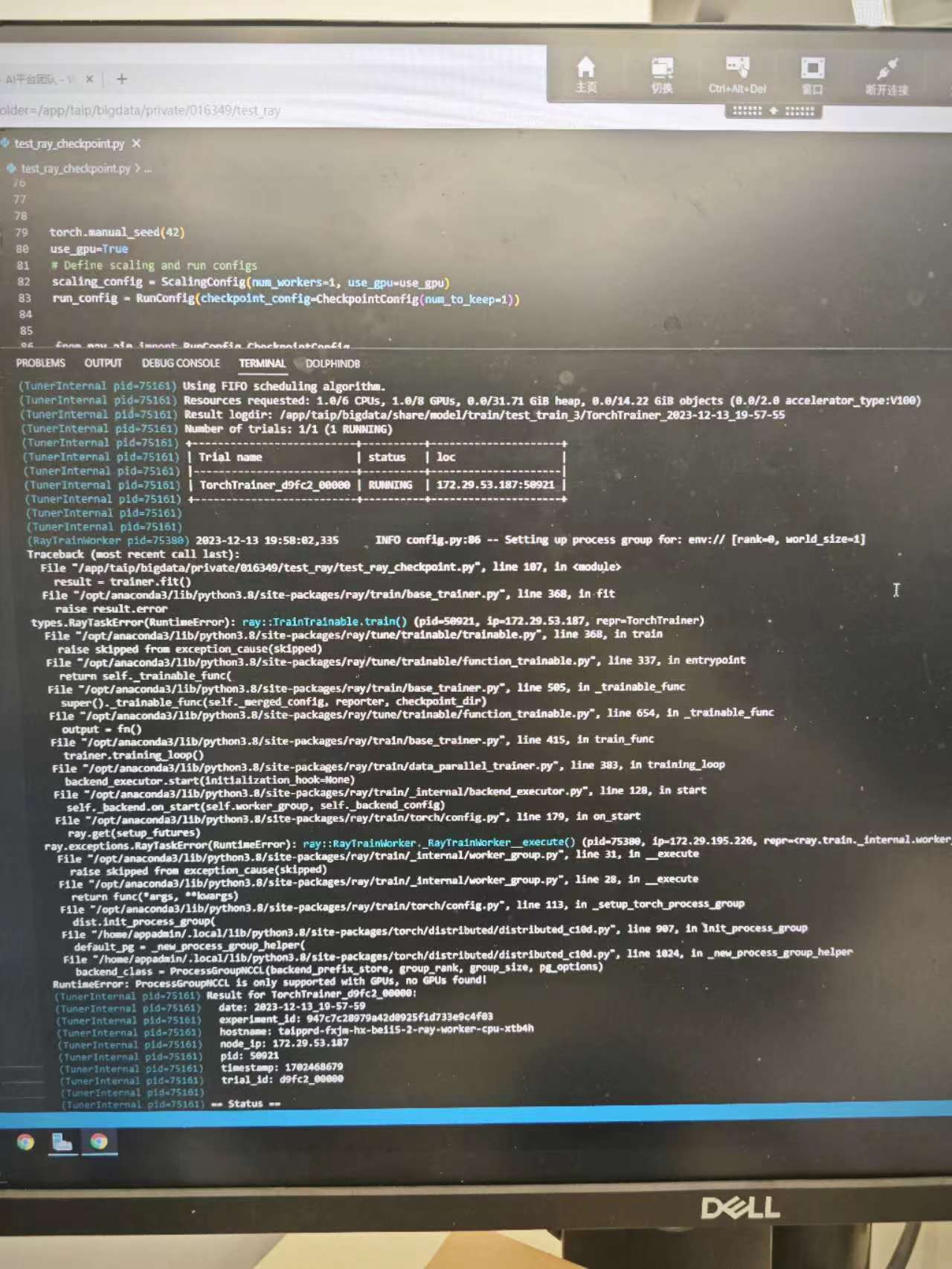
报错现象:
提交任务的时候集群中只有1个cpu类型的worker节点,
用ray trainer训练的时候正常应该是pending,等待gpu节点扩出来,,但是实际现象任务跑到了cpu节点,然后报错。
集群dashboard:
用例