1 问题模板
【Ray使用环境】POC
【Ray版本和类库】1.13.0
【使用现场】
—32台 8卡 NVDIA A100服务器
—基于Ray执行多个torch的ddp训练
【问题复现】
—基于Ray执行多个torch的ddp训练,单个torch ddp训练规模在8GPU到64GPU之间
—出现的问题:在训练过程中,频繁出现worker died的问题 (SYSTEM_ERROR_EXIT错误)导致训练任务异常。具体的log如下:
GCS的log:
[2023-01-07 22:46:34,932 W 3044651 3044651] (gcs_server) gcs_worker_manager.cc:43: Reporting worker exit, worker id = d53f9f3a0ee328581f25f0528850156b577f5388eb8e9f8b0a19d708, node id = 912561135803f170492de14938e6bda6a0109004d512d93084d798d4, address = xxxxxxxxx, exit_type = SYSTEM_ERROR_EXIT0. Unintentional worker failures have been reported. If there are lots of this logs, that might indicate there are unexpected failures in the cluster.
相关的现象为:某一个计算节点上的全部worker会同时因为SYSTEM_ERROR_EXIT0而退出(但是节点上raylet是正常)。例如在32台·A100服务器上,可能在启动5小时后节点A上的全部worker因为SYSTEM_ERROR_EXIT0而退出 (进而导致上面的actor全部crash),但是节点上raylet是正常的。过了几个小时,另外一个节点也会出现同样的问题。
报错的Worker的日志如下:
[2023-01-07 22:46:34,756 I 20699 20793] direct_actor_task_submitter.cc:265: Failing pending tasks for actor 65ddfc5908f14c68ac5c9c9602000000 because the actor is already dead.
[2023-01-07 22:46:34,756 I 20699 20793] direct_actor_task_submitter.cc:283: Failing tasks waiting for death info, size=0, actor_id=65ddfc5908f14c68ac5c9c9602000000
[2023-01-07 22:46:34,756 I 20699 20793] task_manager.cc:419: Task failed: IOError: Fail all inflight tasks due to actor state change.: Type=ACTOR_TASK, Language=PYTHON, Resources: {}, function_descriptor={type=PythonFunctionDescriptor, module_name=xxxxx, class_name=_create_executable_class.._WrappedExecutable, function_name=xxxxxxx, function_hash=}, task_id=e178fb377578209565ddfc5908f14c68ac5c9c9602000000, task_name=x, job_id=02000000, num_args=2, num_returns=2, depth=0, xxxxxxxx, actor_task_spec={actor_id=65ddfc5908f14c68ac5c9c9602000000, actor_caller_id=ffffffffffffffff828e94ccc382067b56eb737702000000, actor_counter=0}, serialized_runtime_env={“envVars”: {“DEBUG_STORAGE”: “False”, “PYTHONPATH”: “xxxxxxx”, “STORAGE_CONCURRENCY”: “False”, “TRANSFER_VALUE”: “False”}}, runtime_env_eager_install=0
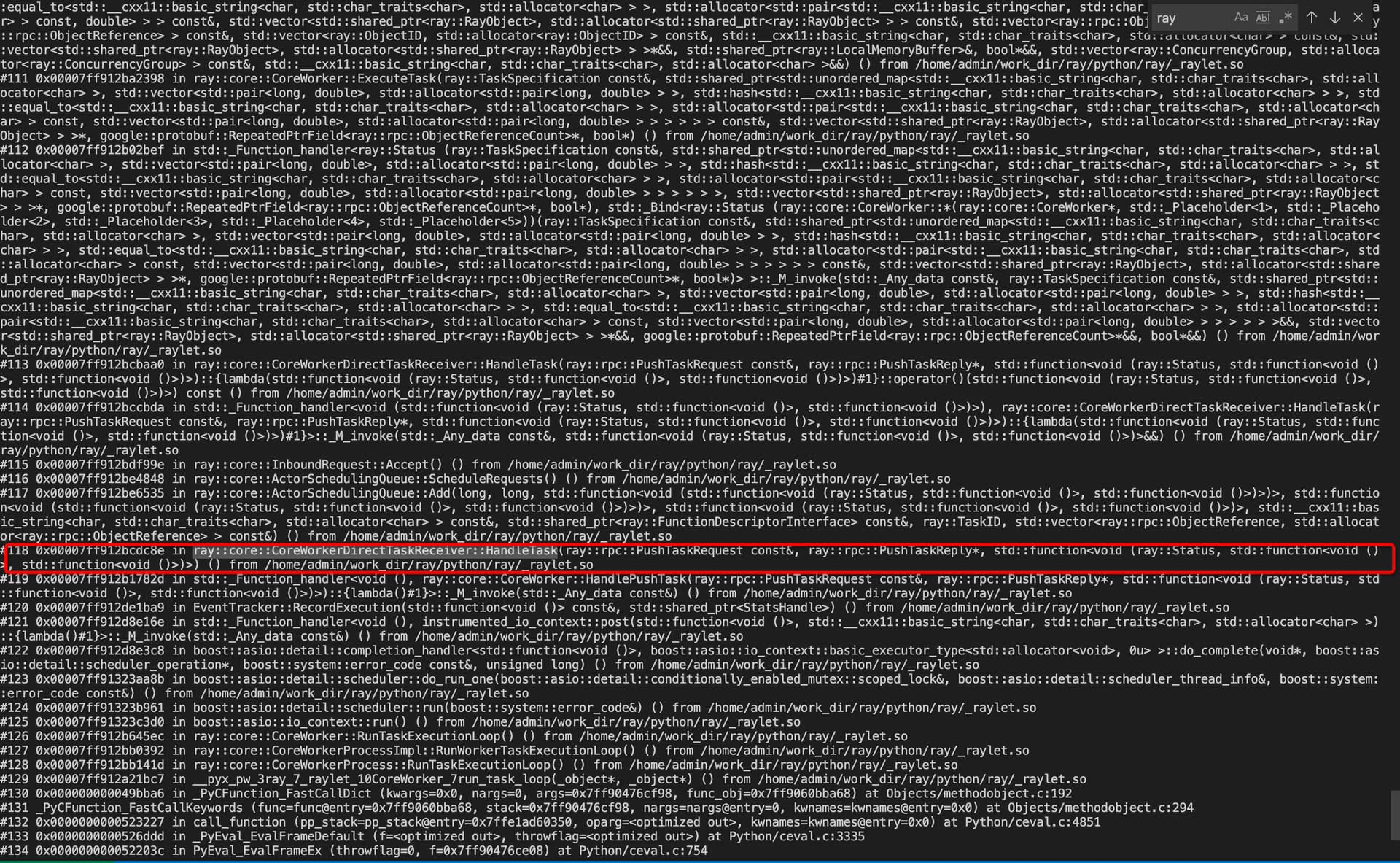
[2023-01-07 22:46:34,881 C 20699 20699] direct_actor_transport.cc:163: Check failed: objects_valid 0 1
*** StackTrace Information ***
ray::SpdLogMessage::Flush()
ray::RayLog::~RayLog()
ray::core::CoreWorkerDirectTaskReceiver::HandleTask()::{lambda()#1}::operator()()
std::_Function_handler<>::_M_invoke()
ray::core::InboundRequest::Accept()
ray::core::ActorSchedulingQueue::ScheduleRequests()
ray::core::ActorSchedulingQueue::Add()
ray::core::CoreWorkerDirectTaskReceiver::HandleTask()
std::_Function_handler<>::_M_invoke()
EventTracker::RecordExecution()
std::_Function_handler<>::_M_invoke()
boost::asio::detail::completion_handler<>::do_complete()
boost::asio::detail::scheduler::do_run_one()
boost::asio::detail::scheduler::run()
boost::asio::io_context::run()
ray::core::CoreWorker::RunTaskExecutionLoop()
ray::core::CoreWorkerProcessImpl::RunWorkerTaskExecutionLoop()
ray::core::CoreWorkerProcess::RunTaskExecutionLoop()
__pyx_pw_3ray_7_raylet_10CoreWorker_7run_task_loop()
method_vectorcall_NOARGS