集群管理
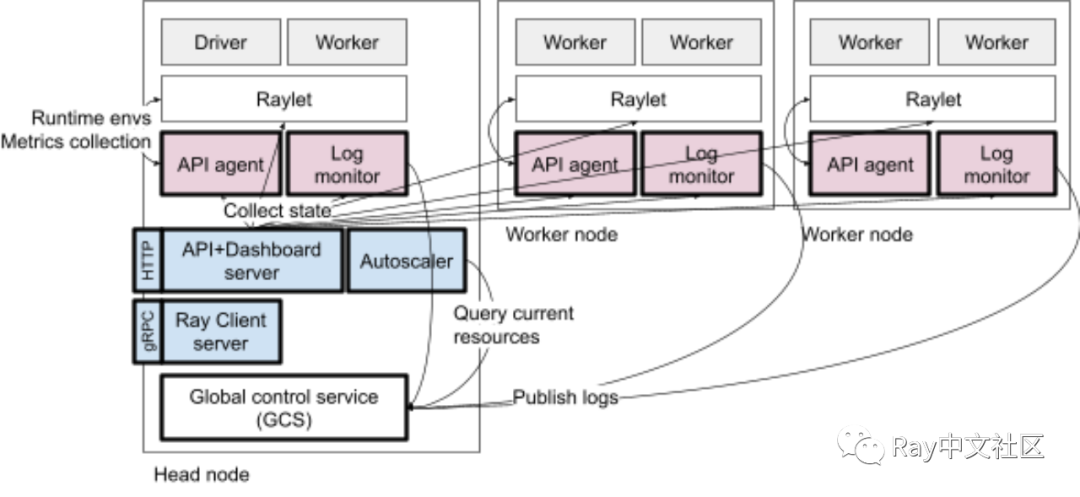
集群管理中涉及的流程。蓝色进程是位于 Head 节点上的单进程。粉色进程在节点启动,并管理其本地节点的辅助进程。
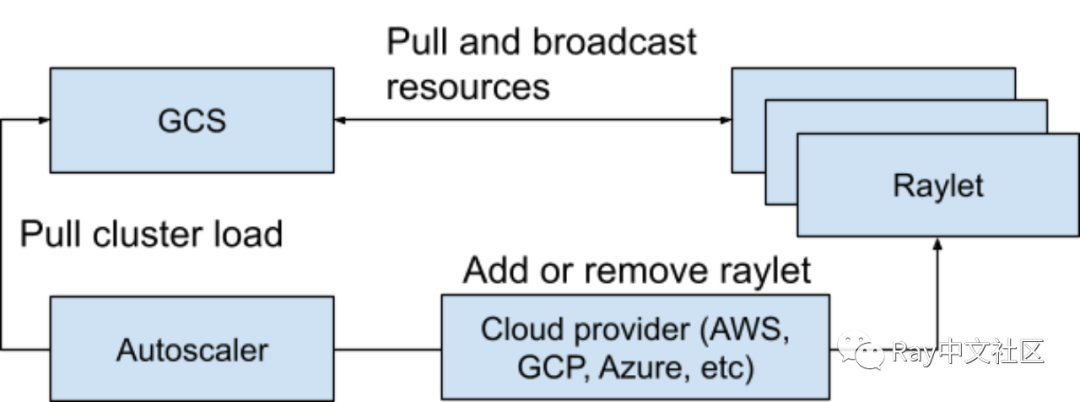
Autoscaler 用于自动缩放,根据节点资源情况和利用率添加或删除节点。
Autoscaler 负责从集群中添加和删除节点。它会监测分布式调度器暴露的逻辑资源需求、集群中当前的节点、集群的节点配置文件,计算所需的集群配置,并尝试扩缩容(比如调用云提供商添加或删除机器)。
Autoscaler 的工作流程如下:
-
应用程序提交任务、Actor、预占用组,这些任务请求诸如 cpu 之类的资源。
-
调度器查看需求和可用性,如果无法满足,则将其置于挂起状态。该信息被快照到GCS 中。
-
自动缩放器作为单独的进程运行,将定期从 GCS 获取快照。它查看集群中可用的资源、请求的资源、挂起的资源、为集群指定的工作节点配置,并运行 bin-packing 算法来计算节点数量,以满足正在运行和挂起的任务、Actor 和预占用组请求。
-
自动缩放器然后通过节点供应商接口从集群中添加或删除节点。节点供应商接口允许Ray 插入不同的云提供商(例如AWS、GCP、Azure)、集群管理器(例如Kubernetes)或本地数据中心。
-
当新的节点启动时,它向集群注册并接受应用程序的工作负载。
如果节点空闲超时(默认情况下为5分钟),则会将其从集群中删除。当没有活动任务、Actor 或对象的主要副本时,节点被视为空闲。
可扩容节点的数量有限制,这取决于扩容速度。速度定义为扩容的节点数与当前节点数的比率。值越高,扩容得越多。例如,如果将其设置为 1.0,则集群的大小在任何时候都最多可以增长 100%,因此如果集群当前有 20 个节点,则最多允许 20 个新增节点。可扩容的最小数量为 5,以确保即使对于小集群也有足够的扩容速度。
Ray 也支持云厂商的不同实例类型和设置镜像、IAM 角色等。还可以指定这个机器是否有特殊资源。
Ray Client server 是 Ray Client 用的代理服务,用于支持集群的交互开发。
API server + Dashbord server,提供仪表盘服务和集群状态管理 API 的入口。
API agent,在本地节点上收集集群管理需要的指标,安装用于任务和 Actor 执行的运行时环境。
Log monitor, 负责监听本地的日志,默认在 /tmp/ray/session_last/logs,如果有错误日志会给到 Driver。
Job 提交
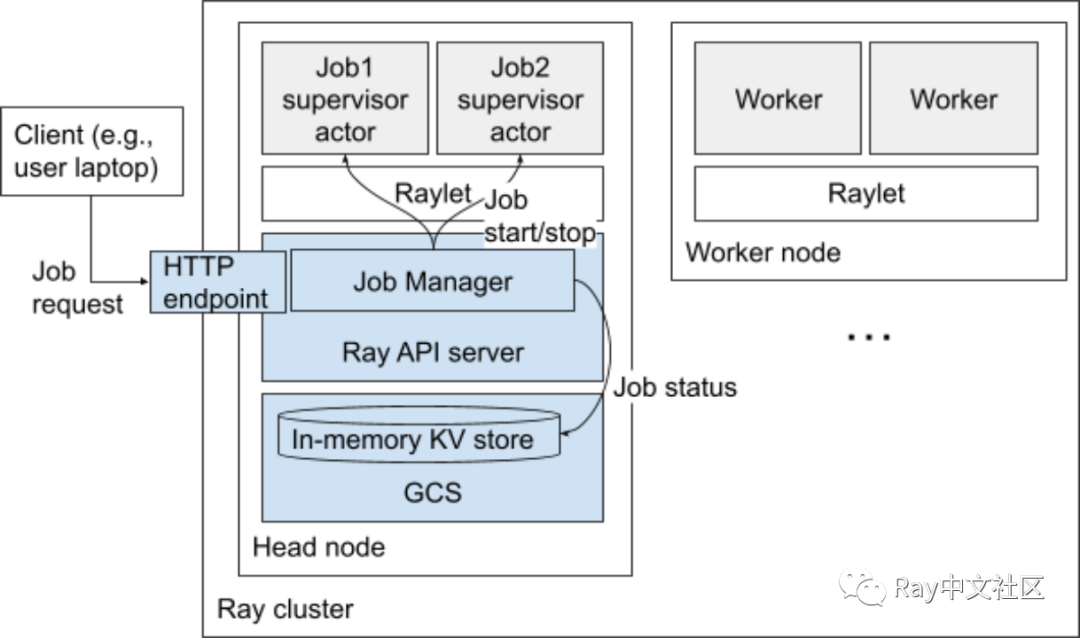
Job 可以通过命令行、Python SDK 或者 REST API 提交到 Ray 集群,CLI 调用 PythonSDK,后者反过来向 Ray 集群上的 Jobs RESTAPI 服务器发出 HTTP 请求。REST API 当前托管在 Ray 仪表板后端,但将来可能会移动到独立的API服务器。
每个 Job 都由自己的专用 Job 主管 Actor 管理,该角色在 Ray Head 节点上运行。这个 Actor 在 Job 的用户指定的运行时环境中运行,Job 的用户指定的端点命令在继承了这个运行环境的子进程中运行。如果这个命令包含 Ray 的脚本,则 Ray 的脚本将附加到正在运行的 Ray 集群。
Job 会报告结构化的状态(如 PENDING, RUNNING, SUCCEEDED)和通过 API 获取到的消息。这些数据都会存储到 GCS 中。
Job 管理的 Actor 及其启动的子流程命运共享。如果 Job 的 Actor 死亡,则保留最新的工作状态。下次用户请求作业状态时,状态将更新为“FAILED”。
通过在相应的 Job 管理的 Actor 上设置“停止”事件,可以异步停止 Job。这个 Actor 会负责终止 Job 子流程,更新其状态并退出。
Job 的管理和 Job 的 管理 的 Actor 和日志会在入口点脚本的输出中直接写入 Head 节点上的文件里,该文件可以通过 HTTP 端点读取或流式传输。
Ray 2.0 允许在除 Head 节点之外调度管理 job 的 Actor,以便减轻多租户的 Head 节点的压力。
运行时和多租户
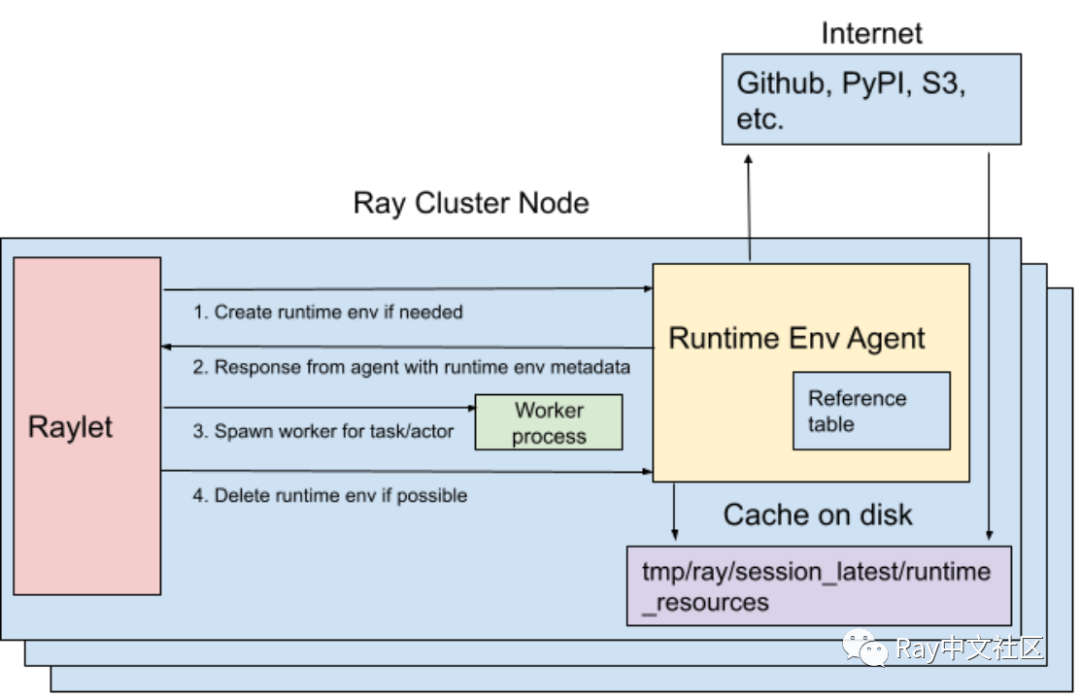
它在运行时动态安装在集群上,可以在 Ray Job 中或特定的 Actor 和任务中指定 Python 脚本运行所需的依赖关系,如文件、包和环境变量。
运行环境的安装和删除由运行在每个节点上的 RuntimeEnvAgent gRPC 服务器处理。RuntimeEnvAgent 命运与 raylet 共享,raylet 是调度任务和参与者的核心组件。
当任务或 Actor 需要运行时环境时,raylet 会向 RuntimeEnvAgent 发送一个 gRPC 请求来创建环境(如果环境还不存在)。
创建环境可能需要做:
- 通过 pip install 下载和安装软件包。
- 为 Ray 的 worker 进程设置环境变量。
- 在启动 Ray 的 worker 进程前使用 conda 切换环境。
- 从远程云存储下载文件。
运行环境资源(如下载的文件和安装的 conda 环境)会缓存在每个节点上,以便它们可以在不同的任务、Actor 和 Job 之间共享。
当超过缓存大小限制时,将删除当前没有 Actor、任务或 Job 在使用的资源。
KubeRay
Kuberray operator 可以在 Kubernetes 设置和管理 Ray 集群。每个 Ray 的节点都作为Kubernetes pod运行在 k8s 上。
可观测性
Dashbord
Ray 提供了像 Dashbord 之类的可视化工具和观测工具来方便检查状态、排查问题。
日志聚合
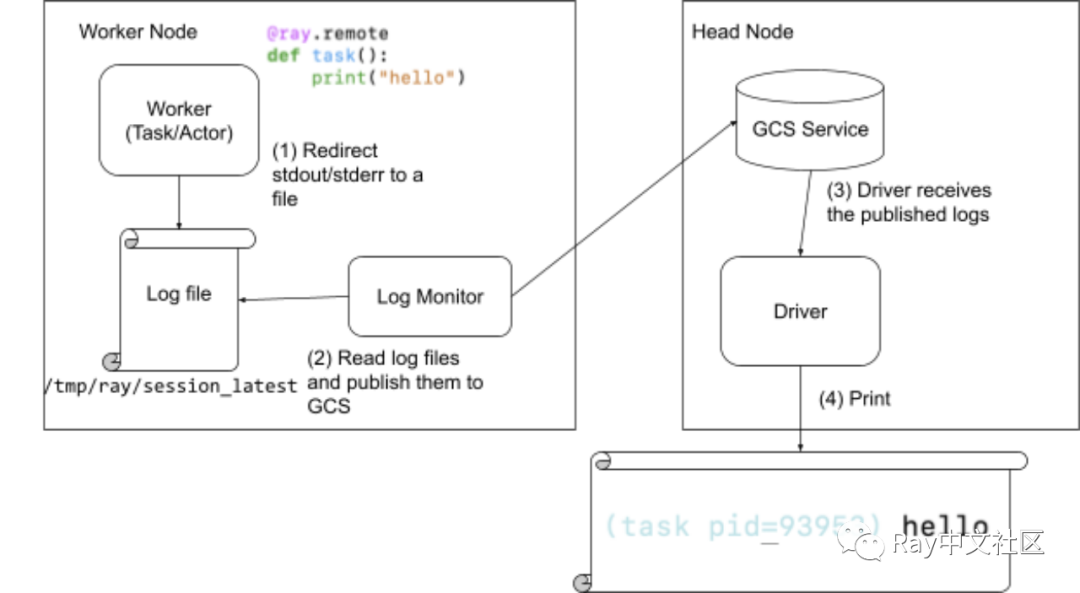
Ray driver 会聚合并输出从 actor 和任务中打印的所有日志消息。当任务或 actor 将日志打印到其 stdout 或 stderr 时,它们会自动重定向到相应的工作日志文件。日志监视器的进程会在每个节点上运行,定时读取并通过 GCS pubsub 将日志发送到 driver。
指标观测
Ray 与 OpenCensus 集成了,默认支持将可以观测的指标导出到 Prometheus。
状态 API
自 Ray 2.0 以来,Ray 支持允许用户通过 CLI 或 Python SDK 方便地访问当前 Ray 的状态的快照。状态 API 支持查询特定 Ray 任务、 Actor 等的查询。
流程详细示例
分布式任务调度
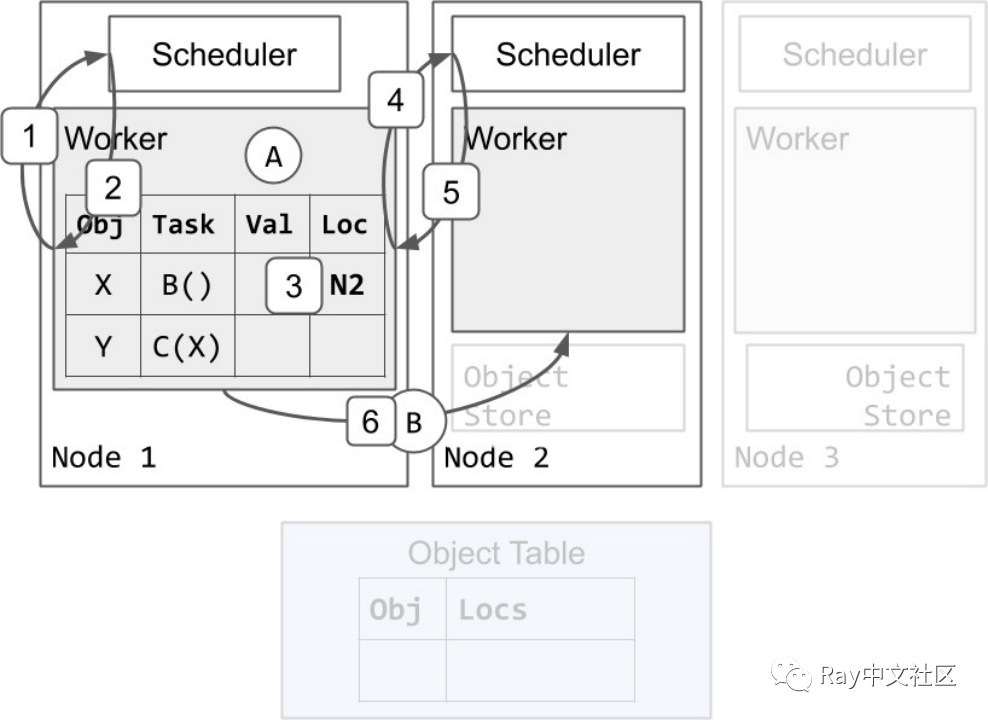
我们将从 worker 1 执行 A 开始。任务 B 和 C 提交给 worker。worker 1 的本地所有权表已经包含 X 和 Y 的条目。首先,我们将介绍一个调度 B 执行的示例:
- Worker 1 向其本地调度器请求执行 B 的资源。
- 调度器 1 作出响应,告诉 worker 1 在节点 2 重试调度请求。
- Worker 1 更新其本地所有权表,要求任务 B 在节点 2 上挂起。
- Worker 1 向节点 2 上的调度器请求执行 B 的资源。
- 调度器 2 将资源授予 worker 1,并用 worker 2 的地址进行响应。调度器 2 确保没有其他任务被分配给 worker 2,而 worker 1 仍然拥有资源。
- Worker 1 发送任务 B 给 worker 2 执行。
任务的执行
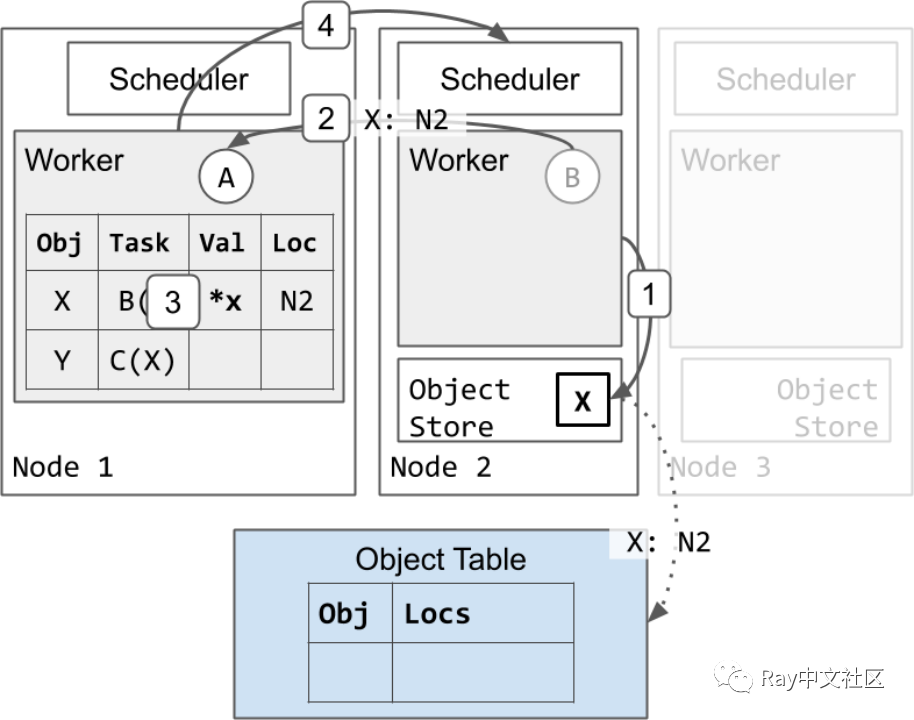
接下来,我们将展示一个 worker 执行任务并将返回值存储在分布式对象存储中的示例:
- Worker 2 完成执行 B 并将返回值 X 存储在其本地对象存储中。
a. 节点 2 异步更新对象表, X 现在位于节点 2 上(虚线箭头)。
b. 因为是创建的 X 的第一个副本,所以节点 2 还固定 X 的副本,直到 worker 1 通知节点 2 可以释放对象。这将确保对象值在引用期间是可访问的。 - Worker 2 回复 worker 1 ,任务 B 已经完成。
- Worker 1 更新其本地所有权表,将 X 存储在分布式内存中。
- Worker 1将资源返回给调度器 2。worker 2 现在可以被重用来执行其他任务。
分布式任务调度和参数解析
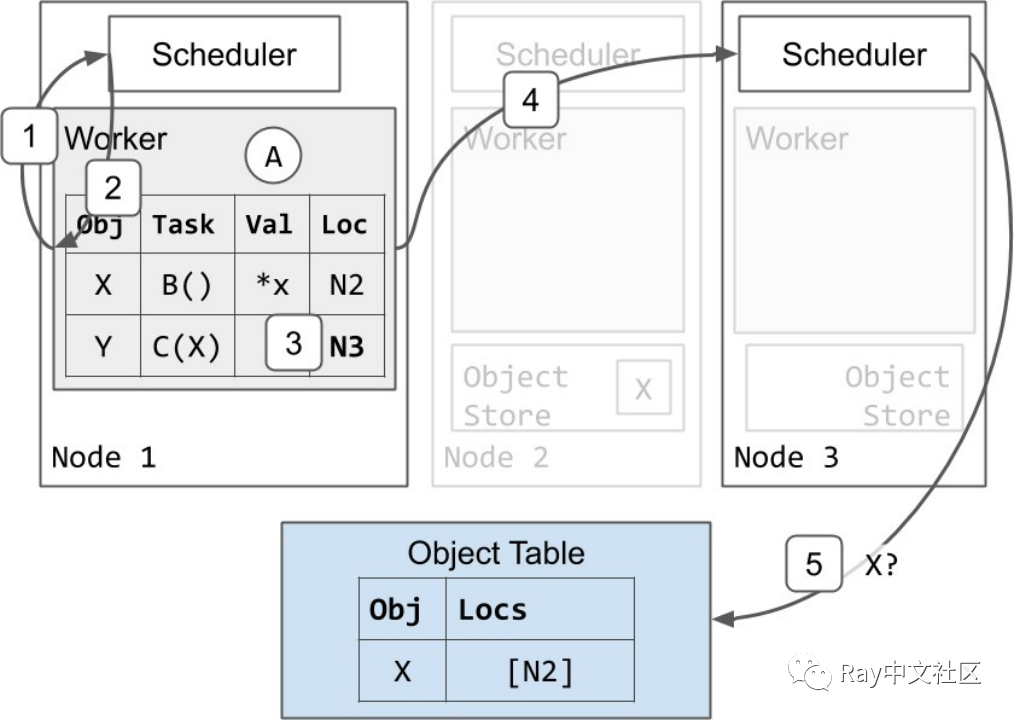
既然任务 B 已经完成,任务 C 就可以开始执行了。Worker 1 使用与任务 B 类似的协议安排下一个任务 C:
- 对象表响应调度器 3,表明 X 位于节点 2 上。
- 调度器要求节点 2 上的对象库发送一份X的副本
- X 被从节点 2 复制到节点 3。
a. 节点 3 也异步更新对象表,表明 X 也在节点 3 上(虚线箭头)。
b. 节点 3 的 X 的副本被缓存了,但没有被固定。当本地 worker 正在使用它时,该对象不会被驱逐。然而,与节点 2 上的 X 的副本不同,当对象存储区 3 处于内存压力之下时,节点 3 的副本可能会根据 LRU 被驱逐。如果这种情况发生,而节点 3 又需要该对象,它可以使用这里显示的相同协议从节点 2 或不同的副本重新获取它。 - 由于节点 3 现在有一个 X 的本地副本,调度器 3 将资源授予 worker 1,并 worker 3的地址作为回应。
任务执行和对象内联
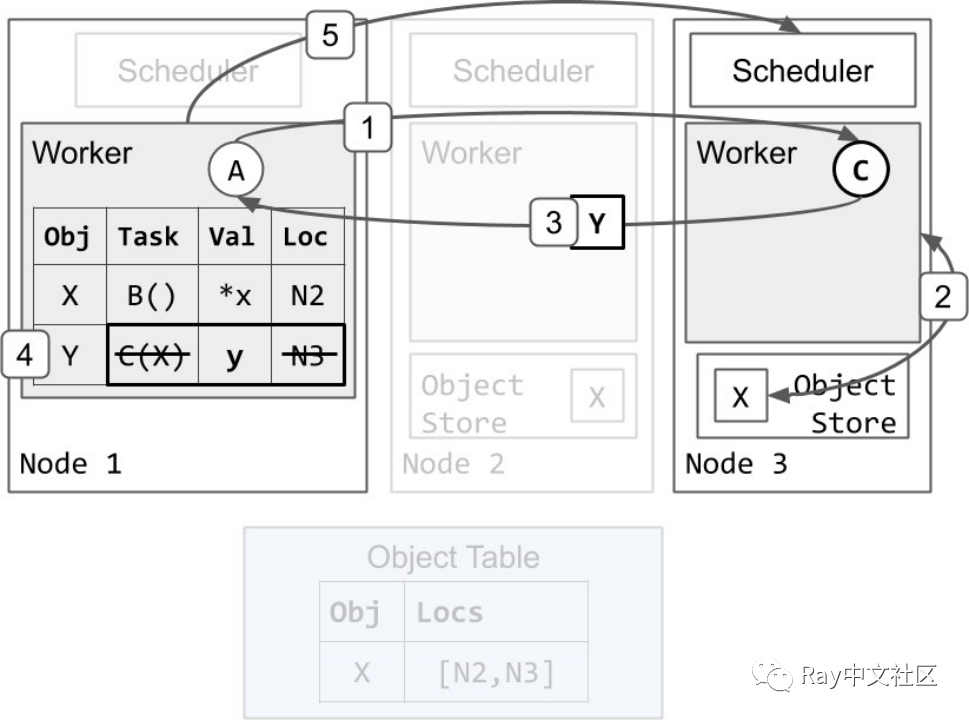
任务 C 执行并返回一个小到足以存储在进程内存存储中的对象:
- Worker 1 发送任务 C 到 worker 3 执行。
- Worker 3 从其本地对象存储中获取 X 的值(类似于ray.get),并运行 C(X)。
- Worker 3 完成 C 并返回 Y,这次是直接通过值而不是存储在其本地对象存储中。
- Worker 1 将 Y 存储在其进程中的内存存储中。它也删除了任务 C 的 specification 和位置,因为 C 已经执行完毕。此时,任务 A 中未完成的ray.get 调用将从 worker 1的进程内存储中找到并返回 Y 的值。
- Worker 1 将资源返回给调度器 3。Worker 3 现在可以被重新使用来执行其它任务。这可以在步骤 4 之前完成。
垃圾回收
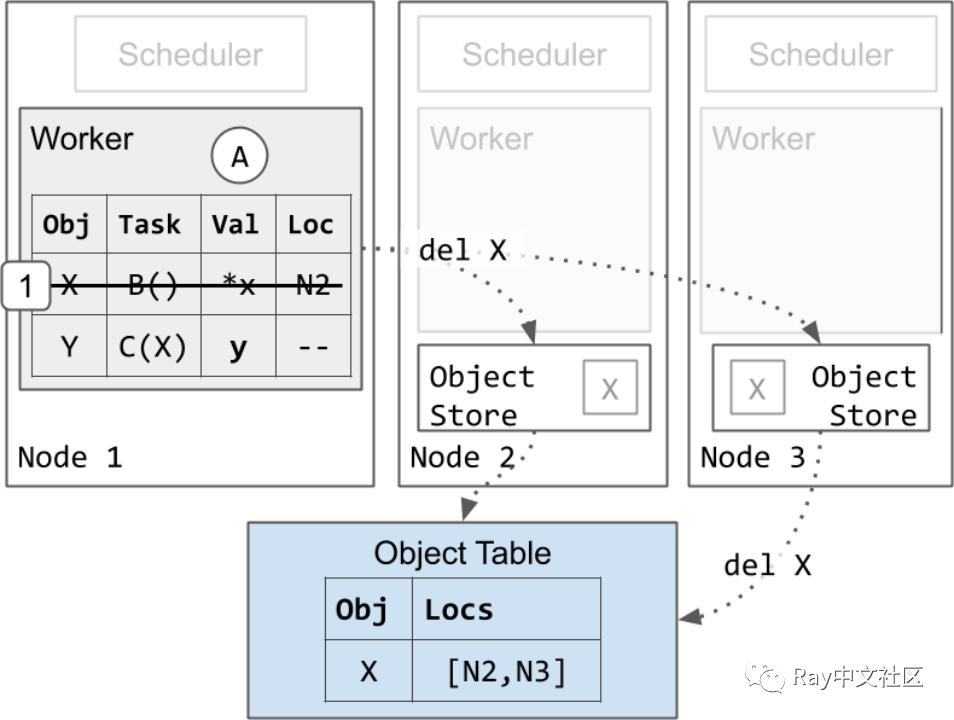
最后,我们将展示 worker 是如何清理内存的:
- Worker 1 删除了对象 X 的记录。这样做是安全的,因为等待中的任务 C 有对 X 的唯一引用,而且 C 现在已经完成了。Worker 1 保留其对 Y 的记录,因为应用程序仍然有对 Y 的 ObjectID 的引用。
a. 最终,X 的所有副本都从集群中删除。这可以在步骤 1 之后的任何时间进行。如上所述,如果节点 3 的对象存储处于内存压力之下,节点 3 的 X 的副本也可能在步骤 1 之前被删除。