【Ray版本和类库】ray-1.13.0, zmq-4.3.4, python-3.8.10,
【操作系统和内核版本】Ubuntu 20.04.3 LTS, Linux version 5.10.0-20-amd64
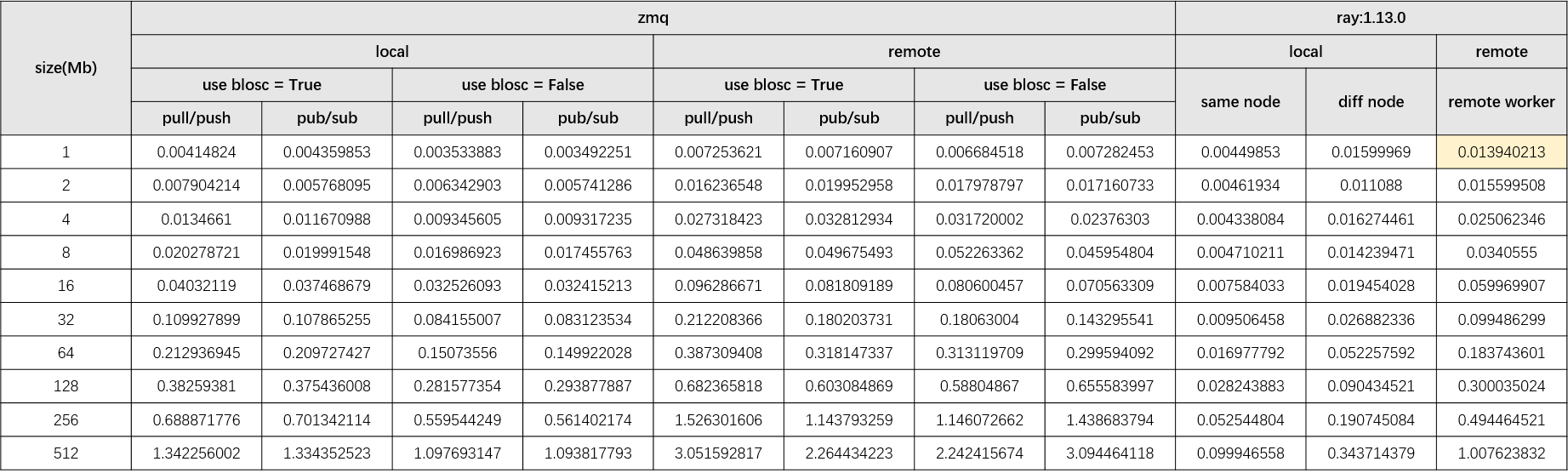
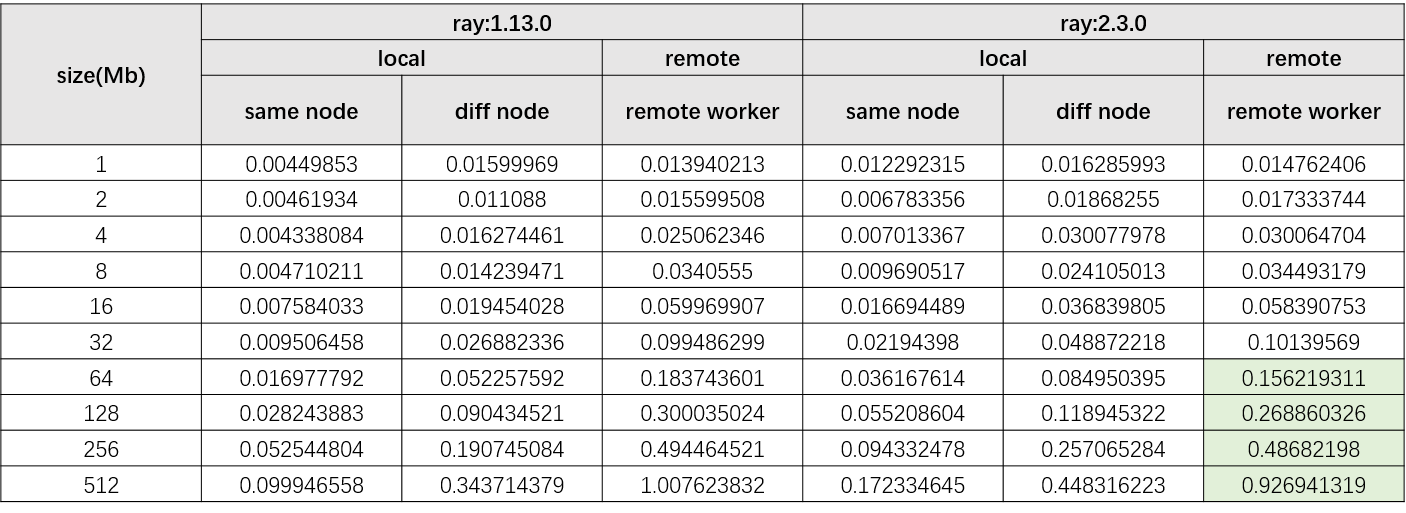
【问题复现】ray在不同节点之间传输不同大小的数据的速度对比
ray.get()的测试代码:
import time
from collections import defaultdict
import ray
from multiprocessing import Event, Process
import numpy as np
class EventProcess(Process):
def __init__(self, begin_event: Event, stop_event: Event):
super().__init__()
self._begin_event = begin_event
self._stop_event = stop_event
generate_large_uint_object = lambda size: np.random.randint(low=255, size=size * 1024 * 1024, dtype=np.uint8)
class TestActor(object):
_name = None
def __init__(self, id):
self.id = id
def name(self):
return "{}_{}".format(self._name, self.id)
if __name__ == "__main__":
test_sizes = [1, 2, 4, 8, 16, 32, 64, 128, 256, 512]
test_round = 100
ray.init(address="auto")
@ray.remote(num_cpus=1, resources={"RemoteWorker": 1})
class RemoteWorker(TestActor):
def __init__(self, id=0):
super().__init__(id)
self._name = "Worker"
self._weight = None
self._cur_round = 0
self._size_map_time = defaultdict(lambda: list())
def ready(self):
pass
def get_weight(self, weight, send_time, size):
self._weight = weight
self._cur_round += 1
recv_time = time.time()
time_consume = recv_time - send_time
self._size_map_time[size].append(time_consume)
def get_final_stat(self):
for size, time_consume_list in self._size_map_time.items():
if len(time_consume_list) > 0:
avg_time_consume = sum(time_consume_list) / len(time_consume_list)
print("{}Mb broatcast to remote worker cost:{} seconds".format(
size, avg_time_consume))
@ray.remote(num_cpus=1, resources={"Router": 1})
class Router(TestActor):
def __init__(self, id=0):
super().__init__(id)
self._name = "Router"
self.remote_workers = [RemoteWorker.remote(i) for i in range(1)]
# wait for worker ready
ray.get([worker.ready.remote() for worker in self.remote_workers])
def ready(self):
pass
def send_to_remote_worker(self, size=1):
for i in range(test_round):
weight = generate_large_uint_object(size)
send_time = time.time()
ray.get([worker.get_weight.remote(weight, send_time, size) for worker in self.remote_workers])
def get_final_stat(self):
ray.get([worker.get_final_stat.remote() for worker in self.remote_workers])
router = Router.remote()
# wait for router ready
ray.get(router.ready.remote())
for size in test_sizes:
ray.get(router.send_to_remote_worker.remote(size))
time.sleep(1)
ray.get(router.get_final_stat.remote())
time.sleep(5)
ray.shutdown()
启动脚本
// Head Node Start command
ray start --head --port 6379 --num-cpus=3 --resources '{"Router":1}' --object-store-memory 3221225472
// Worker Node Start command
ray start --address 'ray-master:6379' --num-cpus=2 --resources '{"RemoteWorker":2}' --object-store-memory 2147483648
这个是zmq和ray在不同条件下对比结果。在数据量为1mb时ray.get()在remote模式下的耗时是zmq的remote模式下的两倍。