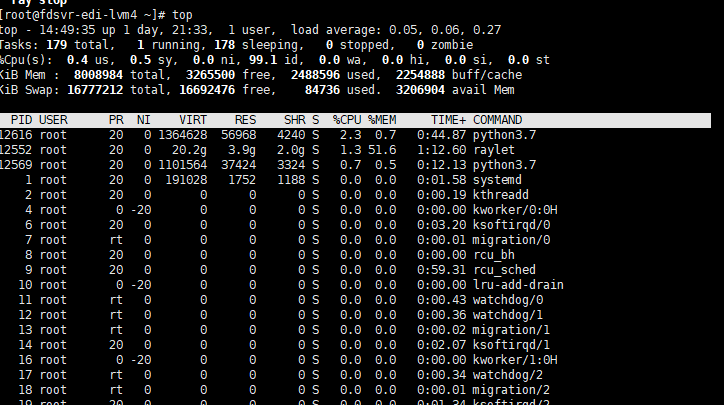
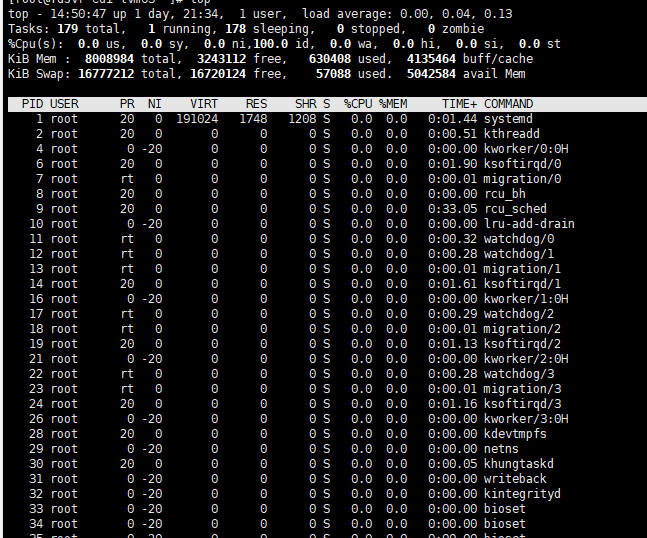
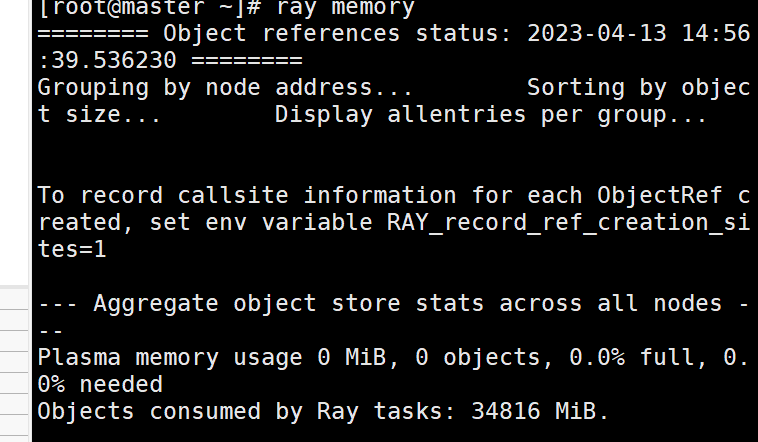
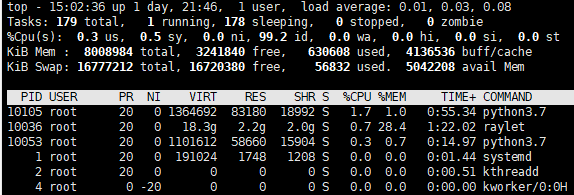
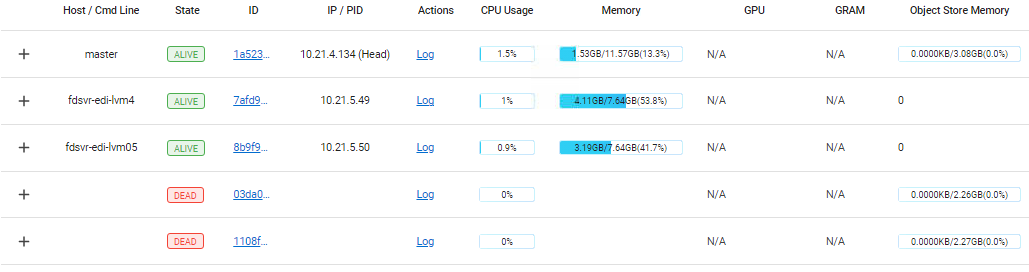
这里进行性能测试的时候遇到了问题,head在不同的节点上定义两个actor,一个发送数据一个接受数据,接受方受到数据就表示收到了然后丢弃。按理来说可以在剩余内存的空间内持续测试,但结果是之前的发送会留下参与内存,最终导致内存溢出,ray自动kill进程。
代码如下:
import ray
ray.init(address=‘auto’)
import time @ray.remote
class MyActor:
def init(self, actor_id):
self.actor_id = actor_id
def send_message(self, message, target_actor):
# 将消息打包成一个对象并发送给目标actor
message_id = message
beg_time=time.time()
target_actor.receive_message.remote(message, self.actor_id,beg_time)
del message
del target_actor
def receive_message(self, message, sender_id,beg_time):
# 从对象ID中获取消息对象并进行处理
del message
t=time.time()
t=t-beg_time
print("收到来自"+str(sender_id)+"耗时:"+str(t))
del t
del sender_id
del beg_time
创建两个actor并相互发送消息
actor1 = MyActor.options(scheduling_strategy= ray.util.scheduling_strategies.NodeAffinitySchedulingStrategy(
node_id=‘2f00d246b672ccf5ce7d8eb1aea40a73f21a9e71d10b4923904d1849’,
soft=False,) ).remote(1)
actor2 = MyActor.options(scheduling_strategy=ray.util.scheduling_strategies.NodeAffinitySchedulingStrategy(
node_id= ‘5a8d371e969e4fe5e3a76a704bd0e349b7a5b5e3b9c985dfb45e846a’,
soft=False,)).remote(2)
for i in range(20):
print(i)
data = b"0" * 1024 * 1024 *1024 *2
actor1.send_message.remote(data, actor2)
del data
一开始的情况:
@ray.remote
class MyActor:
def init(self, actor_id):
self.actor_id = actor_id
def send_message(self,target_actor):
# 将消息打包成一个对象并发送给目标actor
beg_time=time.time()
message=b'0'*1024*1024*1024*5 #修改这里的5则是生成传输数据的大小
c=target_actor.receive_message.remote(message,self.actor_id,beg_time)
beg_time=None
target_actor=None
del message
del beg_time
del target_actor
return c
def receive_message(self, message, sender_id,beg_time):
# 从对象ID中获取消息对象并进行处理
del message
t=time.time()-beg_time
print("收到来自"+str(sender_id)+"耗时:"+str(t))
t=None
del t
del sender_id
del beg_time
return 'get'
执行语句是:
while 1:
D=ray.get(actor1.send_message.remote(actor2))
print(ray.get(D))
del D
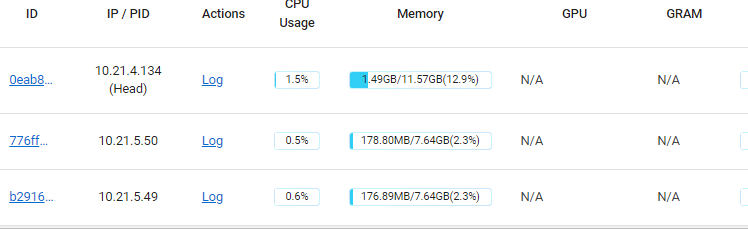
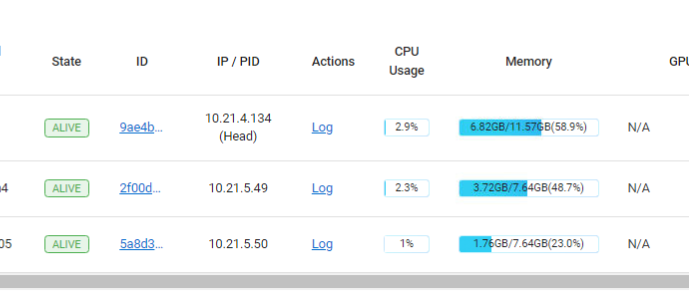
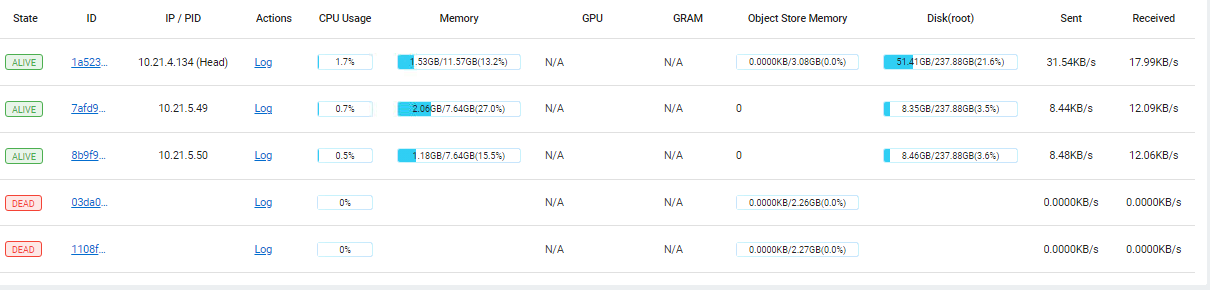
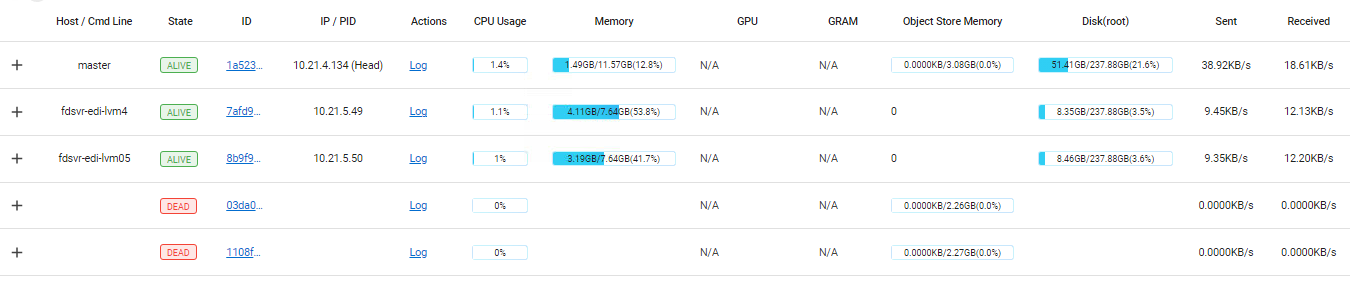
我的配置在dashboard里是(两个从节点关闭重启过):