【Ray版本和类库】ray-1.13.0, zmq-4.3.4, python-3.8.10,
【操作系统和内核版本】Ubuntu 20.04.3 LTS, Linux version 5.10.0-20-amd64
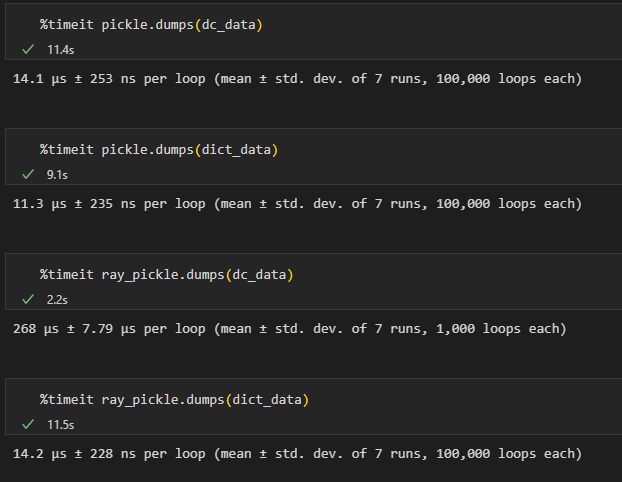
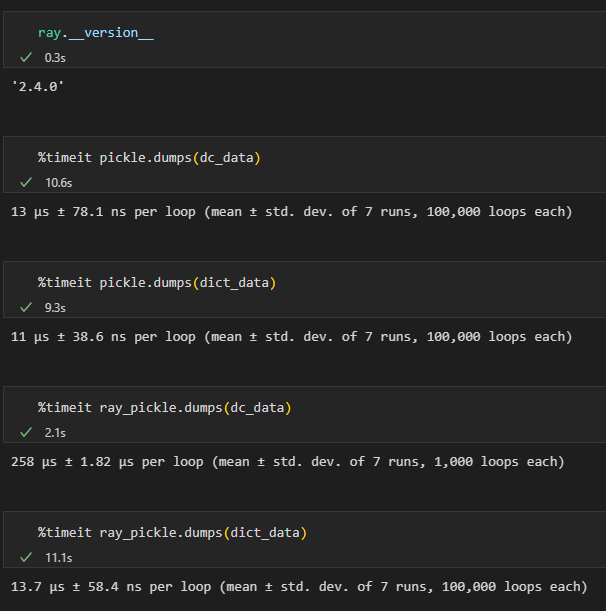
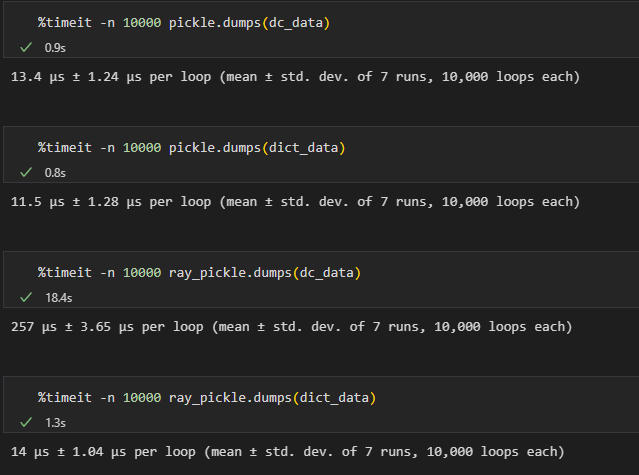
【问题复现】使用ray.cloudpickle和pickle序列化不同类型数据耗时对比
测试代码
import ray
import numpy as np
from dataclasses import dataclass
from typing import List
import pickle
import ray.cloudpickle as ray_pickle
@dataclass
class RLDataPack(object):
exps: List = None
send_time: float = -1.0
worker_id: int = -1
# model_step: int = -1
def generate_class(size):
exp_list = [np.random.rand(size).tolist()]
return RLDataPack(exps=exp_list)
size = 400
dc_data = generate_class(size)
dict_data = {
"exps": [np.random.rand(size).tolist()],
"send_time": -1.0,
"worker_id": -1
}
测试结果,在序列化同样大小的dataclass数据和dict数据时,pickle耗时接近,raypickle对dataclass的序列化慢了一个数量级