zhao
(zhao)
#1
求教各位大佬一个问题,
我在使用ray的过程中发现一个内存用量有点不太对劲的情况,
如下profile的结果,Actor1 向 Actor2发送了一个大概3G左右的numpy array, Actor1对其进行vstack操作之后,此时引用计数清零,但是内存用量为2倍的numpy array。
当重复调用同样的方法时,会发现这3G的内存未被正常释放,但也没有变的更多。似乎是ray自己缓存了一次结果。但是我设置了free_objects_period_milliseconds=0,按说应该能第一时间释放掉?
有什么正确的姿势不做这个缓存么?当类似Actor2数量较多,这个内存放大就很困扰。
(Actor2 pid=24216) Line # Mem usage Increment Occurrences Line Contents
(Actor2 pid=24216) =============================================================
(Actor2 pid=24216) 34 125.1 MiB 125.1 MiB 1 @profile
(Actor2 pid=24216) 35 def get(self):
(Actor2 pid=24216) 36 125.9 MiB 0.8 MiB 1 arrays = self._driver.gen()
(Actor2 pid=24216) 37 # array = copy.deepcopy(array)
(Actor2 pid=24216) 38 125.9 MiB 0.0 MiB 8 arrays = [array for array in arrays]
(Actor2 pid=24216) 39 7754.7 MiB 7628.8 MiB 1 ret = np.vstack(arrays)
(Actor2 pid=24216) 40 7754.7 MiB 0.0 MiB 1 del arrays
(Actor2 pid=24216) 41 7754.7 MiB 0.0 MiB 1 print(ret.nbytes/1024/1024)
(Actor2 pid=24216) 42 7754.7 MiB 0.0 MiB 1 return ret
(Actor2 pid=29293) Line # Mem usage Increment Occurrences Line Contents
(Actor2 pid=29293) =============================================================
##### HOW TO RELEASE THIS 3.9GB? ####
(Actor2 pid=29293) 34 3941.8 MiB 3941.8 MiB 1 @profile
(Actor2 pid=29293) 35 def get(self):
(Actor2 pid=29293) 36 3941.8 MiB 0.0 MiB 1 arrays = self._driver.gen()
(Actor2 pid=29293) 37 # array = copy.deepcopy(array)
(Actor2 pid=29293) 38 3941.8 MiB 0.0 MiB 8 arrays = [array for array in arrays]
(Actor2 pid=29293) 39 7756.5 MiB 3814.7 MiB 1 ret = np.vstack(arrays)
(Actor2 pid=29293) 40 7756.5 MiB 0.0 MiB 1 del arrays
(Actor2 pid=29293) 41 7756.5 MiB 0.0 MiB 1 print(ret.nbytes/1024/1024)
(Actor2 pid=29293) 42 7756.5 MiB 0.0 MiB 1 return ret
示例代码如下:
import ray
import numpy as np
import time
from memory_profiler import profile
class Driver:
def __init__(self) -> None:
self._actors = [
Actor1.remote()
for i in range(5)
]
def gen(self):
return ray.get([
actor.gen.remote()
for actor in self._actors
])
@ray.remote
class Actor1:
def gen(self):
self._x = np.random.rand(100000000)
return self._x
@ray.remote
class Actor2:
def __init__(self, driver: Driver):
self._driver = driver
@profile
def get(self):
arrays = self._driver.gen()
arrays = [array for array in arrays]
ret = np.vstack(arrays)
del arrays
print(ret.nbytes/1024/1024)
return ret
@profile
def x(self):
time.sleep(10)
return 1+1
if __name__ == "__main__":
configs = {
"memory_monitor_refresh_ms": 0,
"memory_usage_threshold": 1,
"free_objects_period_milliseconds": 0,
}
ray.init(_system_config=configs)
driver = Driver()
a2_ref = Actor2.remote(driver)
while True:
ray.get(a2_ref.get.remote())
ray.get(a2_ref.x.remote())
zhao
(zhao)
#4
Ray 2.4.0, python 3.8, linux ubuntu 20.04
3.9GB 应该包括共享内存?你应该是单机测试 Actor1和Actor2在同一个节点吧?如果kill掉所有Actor1,这个3.9GB还有吗?
zhao
(zhao)
#6
对是在单机上测试的,看起来这个3.9G确实是共享内存,当Actor1被删除之后这个部分就没有了。
不过我没太理解的是我的数据在传输过去之后引用计数应该就清零了,但是这部分内存并没有预期的被释放掉,哪怕此时我sleep一会儿似乎也会持续被占用。
@zhao 我理解你现在觉得你 del arrays 之后,arrays 这部分内存没有被释放对吧。如果是这样我我觉得你完全没必要担心,有以下几个点:
- 首先你这样依靠 actor 进程来观测 shared memory 释放的时间节点是做不到的,在
del arrays 之后,依照我的理解,python 的 gc 有没有立刻回收这个 np.ndarray 是不确定的.
- 即使 python 的 gc 立刻回收了 arrays 所引用的所有 np.ndarray 以及下面的 raybuffer,之后 actor 进程还会和本机的 raylet 进程进行一次通讯,来通知 plasma 某段 shared memory 引用计数为0了,可以被清理了。这个过程对 actor 进程来说是完全异步的,actor 进程没有义务确认 plasma 完成了 gc.
- 即使上述 2 所描述的流程在忽略不计的时间内完成了,plasma 也不是把内存还给了操作系统(我理解不同的操作系统上行为不一样,具体的这部分用的是 dlmalloc 的 deallocate),从设计上来说,是吧内存还给了 plasma/object-store(plasma/object-store 会按照用户的设置在 raylet 启动的时候就从操作系统中拿走给定数量的 shared-memoey,虽然最后会 deallocate 掉,可能在 top 上没有显示内存被划掉,但是设计上来说,这部分内存已经被拿走了).
- 从 3 也能看出,shared memory 反正就那么多,你只要确定 plasma 的引用计数没有泄漏就没有啥问题,泄漏造成的后果也就是 plasma 炸了,put、return 大 object、argument size 很大之类的时候会报 object store full 之类的,而不是 OOM.
综上:我觉得通过 profile 来观察 shared memory 没啥意义,这个系统是异步的,我建议你直接观察 top,以及shared memory 被 plasma free 之后,top 上也不一定会有反应,真要测试,我建议你关掉 unlimit 功能,直接 put 来测试 plasma 的容量是不是符合预期。
最后再提一句:free_objects_period_milliseconds 这个参数你的理解稍稍有些偏差,这个是说 Object 全局的引用计数为 0 之后,具有 primary copy 的那个节点,清理被 pin 主的这个副本的间隔时间,而上述提到的引用是 plasma 的引用和这个是不一样的,plasma 的引用只在描述本机有多少个 worker 在应用 shared memory,而这里的 Object 引用指的是 ray 的 Object 在全集群的引用计数,你例子中的 arrays 这个里面是 plasma 的引用
zhao
(zhao)
#8
感谢大佬的耐心解答,我仔细看了一下您的回答,学到了不少东西!!!
但这里可能是我自己对这个问题的描述以及示例代码有些不太清晰,
我们目前发现的比较确定的问题是actor通信会导致shm无法释放。且等待一段时间后这部分未被释放的内存也无法作为普通内存使用
我补做了一些实验想细化一下我的问题,实验代码会附上便于您复现:
实验环境
Ubuntu 20.04, Ray 2.4.0,Python 3.8
内存:256GB, SHM: 128GB
实验:
在机器比较干净的前提下做如下实验:
Actor1(有4个实例)均向主进程发送约 24GB 的数据,总计约4 * 24 GB,此时不会在actor和主进程保留任何数据,等待10秒,理论上此时内存应该都是可用的状态,紧接着在主进程尝试创建10次24GB数据,虽然比较极限但应该是可以创建出来的。
观察:
-
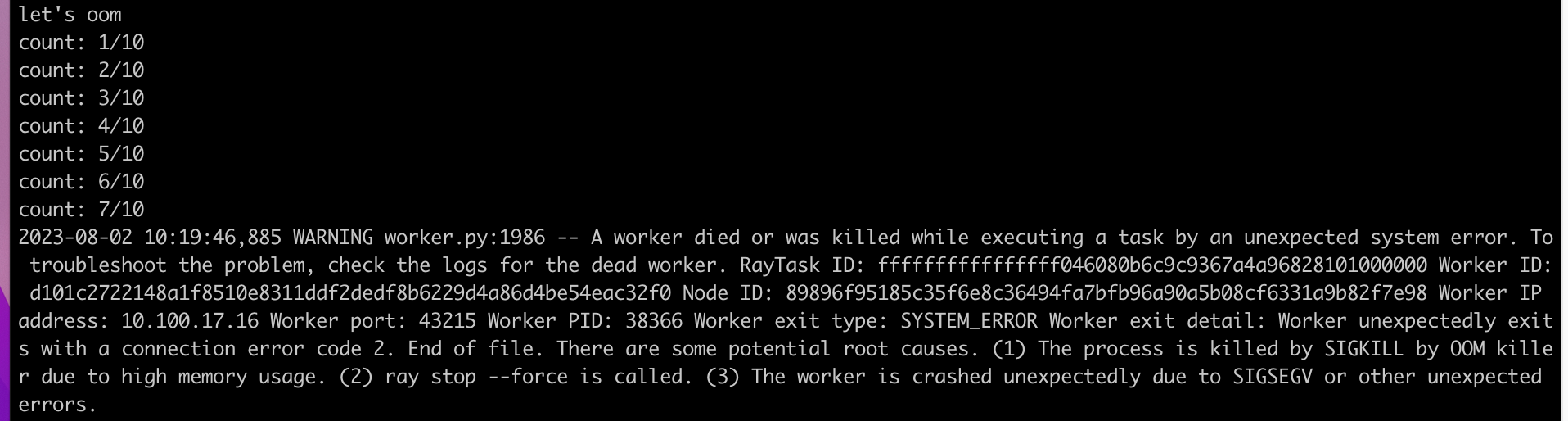
在等待的10秒期间,shared 占了约90GB+
且主进程创建到第7个数据的时候,报错:
-
在等待的10秒期间,top查看内存用量有相应的内存被占用
追加测试0(baseline):不使用ray,本地跑一遍代码流程,可以成功执行
追加测试1:在等待10秒前,删除所有的actor。
结论如观察1,shared依然占了较大的内存,但此时因为ray不参与了,报错变成进程直接被干掉
追加测试2:将Actor1 一次性传24GB数据改成调用100次,每次传0.24GB。
此时shm依然被占用了这么多,结论如上。
追加测试3:将Actor1 给主进程传数据,改成Actor1 给 Actor2 传数据,且数据传输完之后删除所有Actor 。此时shm依然被占用了这么多
测试代码
import ray
import numpy as np
import time
import psutil
class Driver:
def __init__(self):
self._actors = [Actor1.remote() for i in range(4)]
def gen(self):
print(psutil.Process().memory_info().rss / 1024 / 1024)
data = ray.get([actor.gen.remote() for actor in self._actors])
# stacked_data = np.vstack(data)
@ray.remote
class Actor1:
def gen(self):
return np.random.rand(3 * (1024 ** 3)) # ~24GB
if __name__ == "__main__":
configs = {
"memory_monitor_refresh_ms": 0,
"memory_usage_threshold": 1,
}
ray.init(_system_config=configs, dashboard_host="0.0.0.0", object_store_memory=127 * (10**9))
driver = Driver()
driver.gen()
print("sleep...")
time.sleep(10)
print("let's oom")
x = []
for i in range(10):
print(f"count: {i+1}/10")
x.append(np.random.rand(3 * (1024 ** 3)))
zhao
(zhao)
#9
追加一些发现:
这些shm会占据内存,但并不是不可使用,如果对于numpy array的返回值,使用np.copy(RET)将结果拷贝一次之后,反复调用相同的方法,shm不会增加。
看起来,假设func_a会返回一个np array,当调用func_a时,会发生如下情况:
- 首次调用,申请shm来存放np array,
- 目的地如果拷贝了该结果,这个arrow在shm会被释放掉,但是shm本身占得内存依然存在
- 重复调用func_a,shm不会增加
- 但如果目的地没有拷贝,shm似乎会一直增加……
这也导致一个问题,当我ret返回结果较大时,shm用量较多,其他actor的可用内存变少。
zhao
(zhao)
#10
追溯了一下代码,在我可以找到的dlmalloc源码(https://github.com/ennorehling/dlmalloc/blob/master/malloc.c)
里看到这样一段话:
在描述 M_MMAP_THRESHOLD 时提到
- The space cannot be reclaimed, consolidated, and then
used to service later requests, as happens with normal chunks.
看起来通过这种方式申请的内存(对应shm)是不会被释放掉的
然后在这里
看到似乎确实是有一些数据会通过mmap的方式来申请内存,根据实验得出的经验应该是两个actor通信时的数据。
所以出现了我们现在遇到的在ray的生存周期里shm只会越来越大而不能释放。
前面说过,设计上来说,shm 被 object-store/plasma 拿走之后就应该不可以被除了 plasma 以外的组件访问,你的 allocate/free 都应该通过 plasma 的接口来访问。
以及你愿意看代码的话,可以从 raylet/main.cc 入手,我记得有个类叫 StoreRunner,你可以从这里入手看一下 raylet 进程的启动行为,他上来干的第一件事情就是 allocate 一个你指定大小的连续 shm,然后 free 掉(通过这个行为把一个连续的 shm 先申请出来,然后通过 plasma store 的几口 free 掉,表达 store ready 了),以及 dlmalloc.cc 这里面有过逻辑,只有第一次 allocate 的时候才可以 mmap,之后走的都是ray patch的逻辑,以此来保证 allocate 的时候不会申请到之前提到的那块连续内存之外。
综上,对于 ray 来说, shm 没有还给操作系统我觉得是合理的,只要这个 shm 还给了 plasma 就行了。
话说你这个 object store 给了 50% 内存大小么?你要是 oom 的话直接下调 object store 的大小就好了
zhao
(zhao)
#12
嗯感谢大佬,
您的结论和我今天看代码以及近期实验结果基本上是一致的。shm还给plasma但是并没有还给系统,很容易让人误以为是个bug。
这里牵扯到另一个问题,可能是我现在使用不当的一个问题,我们的场景是在两类actor间做非常低频的数据交换,但每次数据量都比较大,而actor自己的处理逻辑又需要占较大的内存,此时正确的内存管理姿势应该是什么呢?
详述一下我们的使用场景:
我们会把原始数据经过一系列处理存放在ActorData里,ActorModel每次会从所有的ActorData中采样约10%左右的数据进行训练,单机场景中,如果直接把所有数据一次性返回,则shm几乎会占到约40%的数据量大小。现在的做法是做batch来减少对shm的占用,但性能上会有一点损失。
我也尝试过直接把原始数据直接ray.put到plasma里,然后由ActorModel侧直接访问源数据并进行采样,但这种方式无法有效利用ActorData的并发来加快采样效率,(并且也可能是我实现的比较垃圾这里观察到了更多的内存用量),导致整体性能降低。
看起来你的 plasma 只作为数据传输使用,我觉得把 plasma 下调就好了
你不需要一次返回,你分批返回,降低 plasma 的峰值大小就好了
zhao
(zhao)
#14
嗯现在确实是这样做的,目前看我们的需求应该是可以满足了,感谢大佬的解答!!!!!